Migrating AWS inputs to Data Manager
Splunk’s Data Manager helps Splunk Cloud Platform users simplify getting data in (GDI) from Cloud Service Providers (CSPs). This article walks you through the main considerations when migrating AWS data inputs to Data Manager, either from an existing data ingest mechanism like the Splunk Add-On for AWS, Splunk projects like Trumpet, or custom developed methods. You can also follow this guidance if you're onboarding AWS data inputs for the first time.
Cloud service providers provide a lot of flexibility when it comes to access to platform data. The Splunk Add-on for AWS helps you access data from those environments through common ingestion mechanisms like S3 buckets. Data Manager improves the data onboarding experience by:
- Replacing manual configurations with automated deployment of data ingestion infrastructure that complies with CSP best practices.
- Improving data collection at scale from multiple AWS regions or accounts in a single input.
- Centralizing data onboarding management across CSPs into a single pane of glass for creating and modifying data inputs.
- Providing an easy-to-interpret interface to monitor and troubleshoot the health of data inputs.
- Eliminating customer-managed app updates and versioning by integrating into Splunk Cloud Platform.
- Maintaining compatibility with Splunk managed apps like The AWS content pack for IT Essentials Work which can be installed through the Splunk App for Content Packs.
These capabilities should be valuable enough for you to transition to Data Manager. You might already have functioning data ingestion approaches that are currently meeting your requirements, and you can continue using those existing methods. However, the next time you need to add a new AWS input, consider using Data Manager.
How to use Splunk software for this use case
Planning migration to Data Manager or first-time onboarding of AWS data
If you're a Splunk Cloud Platform administrator who is ready to take advantage of Data Manager, you should be aware of a few considerations as part of your plan to migrate your AWS input to Data Manager, or onboard AWS data for the first time.
- Review input requirements
- Align inputs with Data Manager capabilities
- Engage with your AWS stakeholders
- Plan your transition
- Configure the Data Manager
- Verify data collection
- Decommission legacy inputs
- Monitor ongoing collection
- Add new inputs
Review input requirements
There are many ways to get data generated on AWS into Splunk. Assess the sources that are currently being ingested and how those sources get into your Splunk deployment. Are data sources configured as an input in the Splunk Add-on for AWS? Are they pushed directly to HEC?
Splunk Add-on for AWS users can review Data Inputs configured in the TA by opening the Splunk Add-on for AWS app and clicking the Inputs link in the green bar at the top of the page. For inputs in the enabled status, ensure you’re seeing corresponding events in search. If not, it might be a good time to clean up any inputs that are no longer in use.
You can also review your HTTP Event Collector (HEC) inputs in the console (Settings > Data Inputs > HTTP Event Collector) for enabled tokens associated with AWS inputs. Validating ingestion of events from these inputs in the Search & Reporting app will help you to identify valid configurations. Confirming the sourcetype by HEC input might reveal conditions where a HEC endpoint is being used for multiple purposes.
Because there are many ways to get data into Splunk, these methods can help you build your catalog. However, they might not be all-inclusive. It's recommended that you engage with your users to understand if there are alternative mechanisms being used to ingest data that might not be clear from reviewing TA or HEC inputs.
Align inputs with Data Manager capabilities
Compare input requirements with existing data manager capabilities. The most commonly ingested data sources are currently supported by Data Manager (CloudTrail, CloudWatch, GuardDuty, etc.). If you have data sources currently collected using another method, consider realigning those data sources to comply with the best practice compliance ingest options supported by Data Manager.
If you don’t see a way to ingest a data source you need to monitor, request a new enhancement via the Splunk Ideas Portal and share it with your Splunk account team.
Engage your AWS stakeholders
Data Manager requires provisioning resources in AWS. In many organizations, making changes to the CSP configurations requires interaction with a cloud administration team. Be sure to communicate the requirement for the cloud team to establish IAM permissions and execute CloudFormation scripts to deploy resources. You’ll want to communicate the data sources you intend to ingest and how Splunk collects those inputs. You should anticipate discussion around data volume (and potential egress charges) as well as infrastructure costs. Information on data ingestion mechanisms and intervals is available in the Splunk Data Manager documentation.
Plan your transition
During the configuration process, Data Manager will provision resources in your AWS environment in order to send data to Splunk. If you have existing inputs, this results in duplicated events until the legacy data ingestion mechanisms are disabled.
Duplicate data ingestion can have significant ramifications for cost and license usage, so make sure you plan the time to configure, verify, and disable the previous inputs during the transition. You might need to break up the migration task into multiple efforts to ensure a smooth, systematic transition.
Configure the Data Manager
The Data Manager console provides in app step-by-step instructions for deploying a Data Manager input. The exact steps vary depending on whether you have a single or multiple account deployment, but the key stages are:
- Deploy prerequisites: Establish a read-only role in your AWS account that allows your Splunk Cloud Platform environment to monitor inputs managed by Data Manager. The role policy is available for review in the Data Manager documentation. In multiple account deployments, prepare your environment to use CloudFormation with self-managed roles.
- Input data collection: Use the Data Manager console to specify the accounts, regions, and resources according to your input requirements.
- Create CloudFormation Stack: The output of the previous step is a cloud formation template. The generated template needs to be imported into the AWS Cloud Formation console to create the necessary stacks, or stackset, based on the selected inputs.
Verify data collection
After the stackset has been created, use the Data Manager console to review and monitor the health of your AWS data inputs. The Data Management screen provides a graphical interface to monitor the state of the input deployments. An “In Progress” message indicates that an input is still being provisioned through CloudFormation and a healthy input will be in the “Success” status. The throughput field should start populating and the “Last Received” field should begin updating as well.
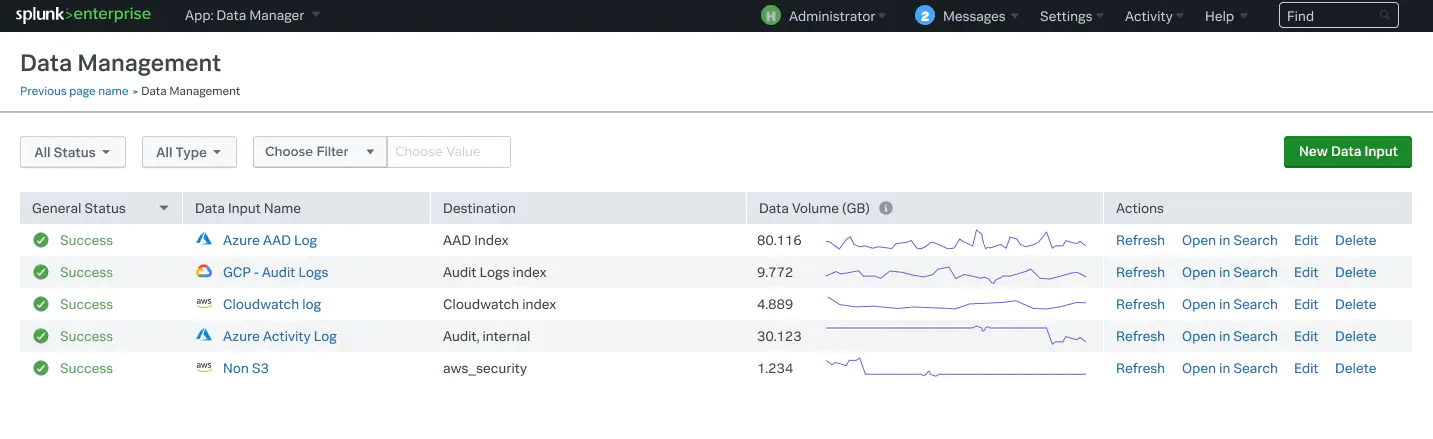
The “AWS Inputs Health” dashboard provides the next level of detail, showing input status by data source and account. The filtering capability provides a way to systematically review the configured inputs against your plan.
If your organization has strict requirements for data collection, you might want to count events by source to confirm that the number of events ingested in a particular time span is the same between your legacy input versus Data Manager. If counts differ, additional investigation may be necessary - for example, you might find that another AWS account is sending data.
Please refer to the Data Manager Troubleshooting Manual if you experience challenges configuring Data Manager. If you continue to experience errors after following any applicable guidance in the Troubleshooting Manual submit a Support case.
Decommission legacy Inputs
Data Manager uses the Splunk Add-on for AWS for Common Information Model (CIM) mapping for AWS inputs, so the Splunk Add-on for AWS should not be removed if you use the CIM.
After you have confirmed that Data Manager has successfully configured resources, data is being ingested, and events collected between the previous ingest mechanism and data manager are consistent, it’s time to decommission legacy inputs to eliminate the now-redundant legacy data inputs. You need to disable the redundant inputs to prevent duplicate data ingestion.
- Customers using the Splunk Cloud Add-on for AWS can disable the input within the Add-on, and click the Status toggle to change the Status state from Enabled to Disabled to stop ingestion from the toggled inputs.
- Customers with manual configurations may need to manually decommission CSP infrastructure.

After disabling inputs, confirm that ingestion from the previous inputs has stopped. If ingestion continues, then you might need to investigate further to identify the source of those events.
If the duplicate events generated during the migration create reporting challenges for your organization, use the Splunk delete command to eliminate the duplicate events from appearing in subsequent searches. Note that the delete command is only an event marker and will not reclaim any storage space.
If you’re ingesting AWS data for the first time, install the Splunk Add-On for AWS before configuring Data Manager.
Monitor ongoing collection
After the Data Manager is up and monitoring ongoing collection, you can use the Data Manager user interface to monitor your inputs.
Add new inputs
If you need to add an input, click Add a new Input in the Data Manager console and redeploy the CloudFormation stack set with the new template.
Next steps
Splunk Cloud Platform offers pre-built apps to visualize your ingested data. The IT Essentials Work with AWS Content Pack replaces the visualizations in Splunk App for AWS that is now end-of-life. You can also use Splunk Enterprise Security which has prebuilt detections to help you immediately start getting value out of your ingested data.
In addition, these resources might help you understand and implement this guidance:
- Splunk Help: Set up Data Manager
- Splunk Blog: Meet the Data Manager for Splunk Cloud