Using Amazon SageMaker to predict risk scores
You are both a Splunk and an Amazon Web Services (AWS) customer working in the financial services industry. Your reporting shows a number of entities whose accumulated risk scores are close to your user-defined threshold for fraud alerting, but they do not exceed it. For example, your threshold value is 58, and you have an entity with accumulated risk scores of 54, 55, and 56 in a three day period. A human can detect that this is an upward trend and react to it, but your analysts have hundreds of thousands of entities, so asking them to look at a series of reports is not a good solution.
You could lower your threshold to include them in risk reporting, but doing so increases false positives. Too many false positives put an unnecessary burden on the customers of a company and also on your fraud department.
Instead, you want to use machine learning or AI to predict that a boundary fraud score might, in the near future, cross the threshold so you can take action now. While you use the Splunk platform as a data aggregator and analytics engine, you are more comfortable with Amazon tools than with Splunk add-ons. You want to use Amazon SageMaker to deploy machine learning models to predict customers who might engage in fraud, based on their past risk scores.
Data required
How to use Splunk software for this use case
In the Splunk platform, scheduled searches run against rules, which in turn use transaction data, to calculate risk scores for fraud detection. Those risk scores along with metadata are stored in a summary index. From there, you can use a third-party application, like Amazon SageMaker, to read the data from the risk index for further analysis.
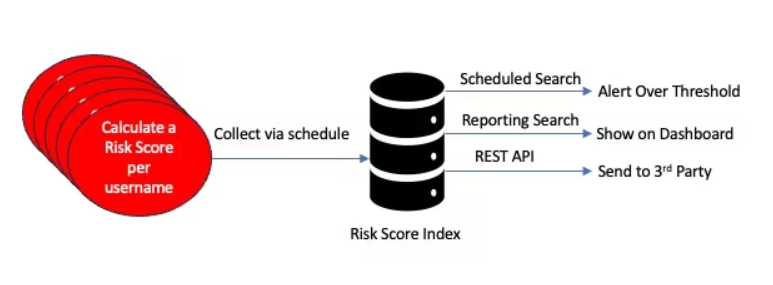
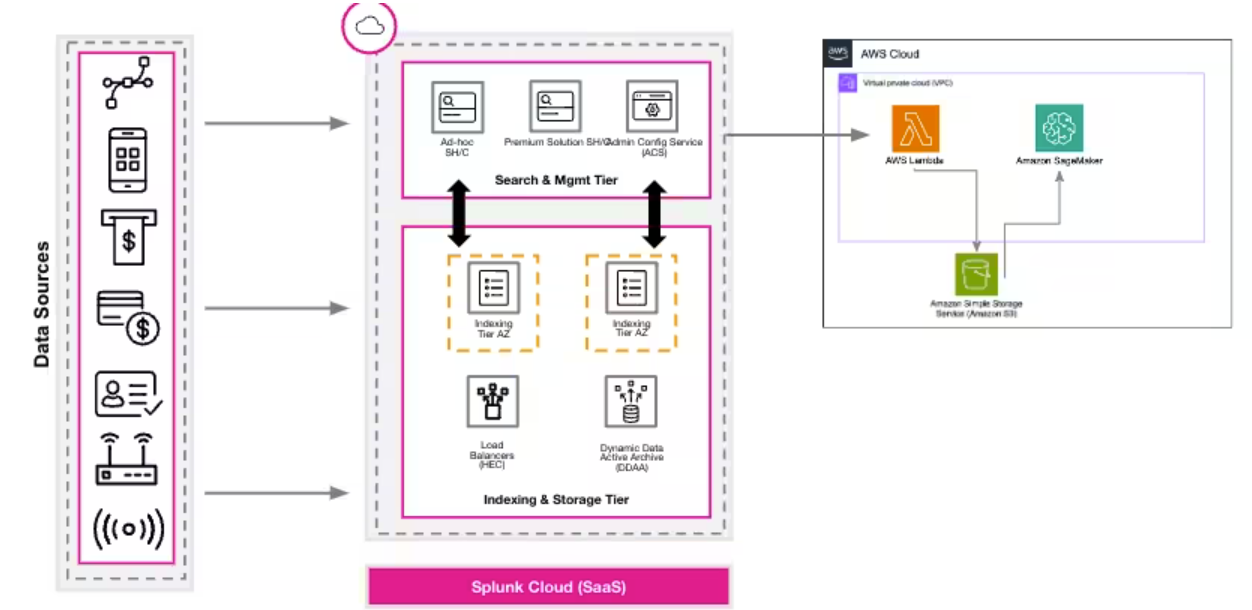
Use a scheduled AWS (Lambda) function in AWS to query aggregate risk scores (and metadata like timestamps, names of rules, and entity name) from the Splunk platform using a REST API and place the results into Amazon (S3) buckets. In the diagram below, the box on the right is AWS, which might be the same cloud instance as the Splunk Cloud Platform, in which case there would be no egress cost to send data from the Splunk Cloud Platform to AWS. Then, Amazon SageMaker can query the S3 buckets to build a model to predict future risk scores per entity.
After the data is collected, use Amazon SageMaker to create models and do numerical forecasting with the time series data. While you'll need to refer to SageMaker documentation for more specific help with this procedure for predicting future risk scores, the high-level steps are:
- Create a predictive model.
- Validate the data and quick build.
- Analyze and determine column importance.
- Validate model accuracy.
- Try predicting based on inputs.
Let’s dive deeper into step 4. The line on the graph below represents predicted values. Some of the actual values (the dots) are just below the prediction. These are the entities that might turn out to be fraudsters if their predicted risk score is higher than our threshold value. This is what you are looking for in this use case.
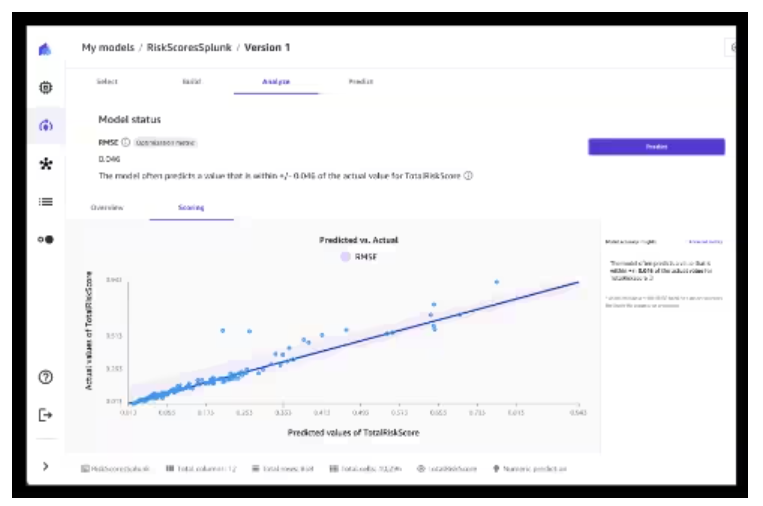
What algorithm was used to predict summarized fraud scores per entity? Several were utilized in the family of linear regression to predict the fraud score based on the provided attributes. Neural networks and deep learning could also have been used here with a larger data set.
One interesting takeaway from this exercise was to let us know which fraud detection rule activity contributed most to the accumulated risk scores per entity. When our team ran this use case internally at Splunk, that rule was "Excessive login failures followed by a successful login.” Knowing this, in calculating the total risk score per entity, we might want to multiply this particular risk score by a weight, such as 1.5. to give it 50 percent more importance, as this detection rule has been shown to contribute to fraud more than others. You should analyze and apply your results in a similar manner.
Another interesting note is that Amazon SageMaker works with Open Neural Networks Exchange (ONNX), which is a common format for machine learning models. If the model used in Amazon SageMaker is exported to ONNX format, then the Splunk AI Toolkit can import and inference it. This allows a degree of interoperability, which lets users familiar with the AI Toolkit continue working with models that were developed in other frameworks.
A final point is that the free Splunk App for Data Science and Deep Learning (DSDL) can further be used by data scientists to produce even more comprehensive use cases with deep learning models, giving the Splunk user a variety of choices for their solutions.
Next steps
This article has shown a way to bring fraud detection data into a third party and let the third party software add value to the initial use case. While the Splunk platform and its add-ons also offer these capabilities for advanced use cases, the point is to show that Splunk customers can use products of their choice to enhance a use case initiated in the Splunk platform. If you are a user of Amazon SageMaker, consider using the data that is already in your Splunk Enterprise or Splunk Cloud Platform instance on AWS for your forward-thinking use cases involving fraud detection. If you have not yet used the Splunk platform for fraud detection, click here to get started.
- Splunk Blog: Using Amazon SageMaker to predict risk scores from Splunk
- Splunk Lantern Article: Using modern methods of detecting financial crime