サプライチェーンの問題の特定と視覚化
現代のサプライチェーンは、国境や規制要件など、複数の場所にわたる貨物の管理において複雑に直面しています。在庫レベルをリアルタイムで把握できないことが多く、これが在庫切れや非効率的な資源配分につながります。手作業によるデータ収集や断片化されたシステムでは、遅延やエラーが発生し、可視性が低下します。これらの問題は、顧客の不満、ビジネス上の損失、ブランド評判の低下につながります。
必要なデータ
- GPS データ
-
サプライヤーと調達に関するデータ
- 在庫管理システムまたは倉庫在庫データ
- 位置データ (倉庫と流通ポイント)
このユースケースで Splunk ソフトウェアを使用する方法
Splunkプラットフォームといくつかの便利なSplunkbaseアプリを使用すると、サプライチェーン、倉庫の在庫、スケジュール検索を視覚化して、定期的に自動的に更新情報を取得できます。
- Splunk DbConnect データベースからロケーションとインベントリデータを取得するために使用できます。
- Splunk ロケーショントラッカー さまざまな倉庫や配送エリアなど、複数のロケーションを一度に追跡できます。
サプライチェーンを視覚化する
データを取り込んだ後の最初のステップは、データをマップ上に配置することです。これは、物理的な場所 (倉庫、店舗、施設など) と追跡したい移動品の両方を対象としています。
これは、地理情報システム (GIS) データベースから取得したデータを使用し、Splunk Location Tracker を使用して視覚化することで実現できます。このデータセットを作成する簡単な方法は、必要な部分だけを取り出すことです。これには、未使用のデータが含まれないので、ダッシュボードが高速になるという利点もあります。
次のような SPL を使用できます。
| index=<"location data index"> sourcetype=<"location data sourcetype"> | table _time latitude longitude identifierField | sort -_time
検索の説明
| Splunk Search | 説明: |
|---|---|
| index=<"location data index">
|
「ロケーションデータインデックス」インデックスで「ロケーションデータソースタイプ」ソースタイプを検索します。 |
| table _time latitude longitude identifierField
|
特定のフィールドを選択して表示する (
この検索では
|
| sort -_time
|
に基づいてイベントを降順にソートします。
_time
フィールド。最新のイベントが出力の最初に表示されます。
|
倉庫の在庫を視覚化
2 番目のステップは、各場所に何があるかを示すことです。そのためには、倉庫と在庫のデータが必要です。
デプロイメントで各ロケーションのインベントリデータを取り込んだら、を使用してそれをマップ上に表示できます。
geostats
コマンド。これを実現するためのサンプル検索を以下に示します。
| index=<"inventory data index"> sourcetype=<"inventory data sourcetype"> | stats count BY <"the things you want to count in your inventory"> | geostats latfield="latitude" longfield="longitude" count BY <"the thing you wanted to count earlier">
検索の説明
| Splunk Search | 説明: |
|---|---|
| index=<"inventory data index">
|
「ロケーションデータインデックス」インデックスで「ロケーションデータソースタイプ」ソースタイプを検索します。 |
| stats count BY <"the things you want to count in your inventory">
|
統計計算を実行して、フィルターされたイベントから選択したフィールド内の特定の値の出現回数をカウントします。指定したフィールドはグループ化に使用され、結果の数が個別値ごとに表示されます。 |
| geostats latfield="latitude" longfield="longitude" count BY <"the thing you wanted to count earlier">
|
緯度フィールドと経度フィールドに基づいて地理統計学的集計を生成します。「以前にカウントしたかったこと」フィールドの一意な値ごとに出現回数が表示され、対応する地理的位置が視覚化されます。 |
検索のスケジュール設定
最後のステップは、これらの検索をデータにとって適切な間隔で実行するようにスケジュールすることです。たとえば、アイテムが毎日施設に出入りするだけの場合は、これらの検索を 1 日 1 回実行すれば十分です。ただし、施設内に常に品目が出入りしている場合は、5 分おきに、または 1 分ごとに検索を実行したほうがよい場合があります。
JSON を直接編集し、更新フィールドを希望する時間枠に設定することで、ダッシュボードスタジオ内からこれを行うことができます。このようになるはずです。
"reportNoScheduleWithRefresh": {
"type": "ds.savedSearch",
"options": {
"ref": "Current Time",
"refresh": "5s",
"refreshType": "interval"
},
「refresh」フィールドが表示されない場合は、JSON にフィールドを追加し、時間間隔を追加するだけで、自動的にスケジュールされます。
すべてを読み込むと、次のようになるはずです。
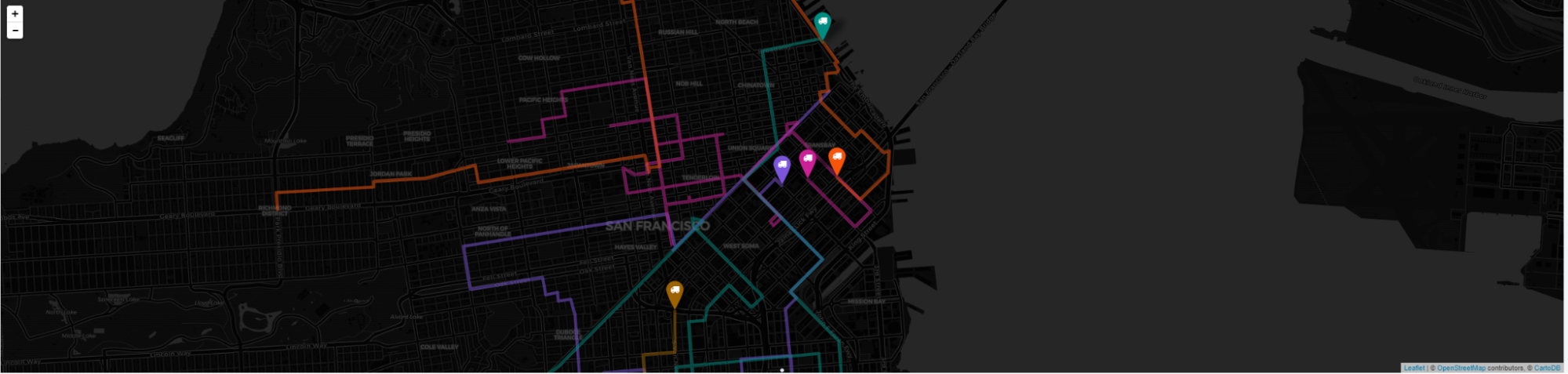
次のステップ
サプライチェーンのロジスティクスを監視できたので、ルートの効率性をさらに掘り下げて、顧客が品目を要求している場所について詳しく知ることができます。このデータを使用して、倉庫内の品物の保管方法と保管場所を決定することで、よりスムーズで迅速なロジスティクスプロセスを実現できます。
さらに、以下のリソースは、このガイダンスの理解と実装に役立つ場合があります。
- Splunk ブログ: サプライチェーンのすべて
- スプランク・ランタンの記事: 製造現場でのユースケース