Partitioning data in S3 for the best FS-S3 experience
Splunk Federated Search for Amazon S3 (FS-S3) allows you to search data from your Amazon S3 buckets directly from Splunk Cloud Platform without the need to ingest it. Splunk documentation includes detailed information on Federated Search configuration, but the use of AWS Glue introduces data partitions, partition indexes, and projections where the implication and importance of these concepts might not be clear.
Federated Search for S3 licensing is based on Data Scan Units (DSUs), and DSUs are consumed based on the data volume scanned. Defining Glue table partitions and crafting your searches to use partition keys with your WHERE clauses can limit the amount of data scanned during searches and help you get the maximum value out of your data scan units. This example includes several search examples that can help you refine your search experience and reduce consumption of your DSUs.
Familiarity with Amazon S3, AWS Glue, AWS Athena, and Splunk’s federated search for Amazon S3 is assumed. If any one of these topics is not familiar, consider taking a few minutes to review those topics or make sure the documentation is on hand.
Why partition data?
Data partitioning is an approach to organizing datasets so they can be queried efficiently. When properly partitioned, data in your S3 bucket is organized into a directory structure based on one or more unique partition keys. The most common way to do this is to have different file (object) paths in S3. FS-S3 can take advantage of partitions to reduce the amount of data scanned in a search. This can reduce query time and the licensing entitlement consumed in a search.
Let’s look at a simple example. In the directory structure below let’s assume you are consolidating logs from multiple applications to a single Amazon S3 bucket. You might create a path in S3 for each application so that all the logs from the different applications are organized into the different paths. In this example, assume the application names are eCommProd, eCommDev, and eCommStage, resulting in the following folder structure:
s3://S3_bucket_name/eCommProd/
s3://S3_bucket_name/eCommDev/
s3://S3_bucket_name/eCommStage/
Without partitioning, any time an FS-S3 query is run it scans all the data in all three application folders. At low volumes this might be acceptable, but as data volume grows, limiting search so it only scans the files associated with the desired application being queried for can prevent consumption of more DSUs than necessary.
The AWS Glue table definitions describe the shape of the data including how the data is partitioned. Tables can be created using a variety of methods, but this article focuses on creating tables using Data Definition Language (DDL) using Amazon Athena in examples.
In terms of identifying the partition structure of your dataset, there are two mutually exclusive configurations: Partition projection and AWS Glue partition indexing.
How to use Splunk software for this use case
Partition projection
Partition projection calculates partitions based on predefined parameters and not the AWS Glue catalog. This is desirable in some scenarios as it removes the need to automate partition management. Let’s explore a few examples of how partition projections can be defined using DDL.
The snippet below includes the TBLPROPERTIES portion of a Glue table definition using DDL, illustrating a simple example of partition projection. DDL must be used to create partition projections. In this DDL, the partitions are described as an enumerated (enum) type and the values for the application projections are supplied. With the partitions and projection defined you can submit federated search queries to the defined partitions.
TBLPROPERTIES ( 'projection.enabled'='true', "projection.appname.type"="enum", "projection.appname.values"="eCommProd, eCommDev, eCommStage", )
Let’s extend this example now and partition the data by the application name and by date, as shown in the example below. Partitioning this way provides the added benefit of being able to limit your data scans much more granularly, down to the day in this example:
s3://S3_bucket_name/<AppName>/2023/03/01
It’s much less practical to enumerate every year, month, and day, like in the first example shown above. Using partition projection to calculate the partitions from a defined pattern is useful for hierarchies, like dates, where the structure is known in advance. Additional information on supported projectable structures is available in the Amazon documentation.
TBLPROPERTIES ( 'projection.enabled'='true', "projection.appname.type"="enum", "projection.appname.values"="eCommProd, eCommDev, eCommStage", 'projection.date.format'='yyyy/MM/dd', 'projection.date.interval'='1', 'projection.date.interval.unit'='DAYS', 'projection.date.range'='2017/01/01,NOW', 'projection.date.type'='date', 'storage.location.template'='s3://S3_bucket_name/’ )
In the TBLPROPERTIES the partition structure is defined based on the date by specifying the date format, the interval and interval unit (in this case, calculating a partition for each day), the date range (start and end dates), and the type. Combining these partitions provides the ability to be very targeted in your data scans.
Partitions will be projected even if they are empty. While this does not result in an error, too many empty partitions are likely to result in performance being slower than partitioning indexing. As a rule, if more than half of your projected partitions are empty, you should use partition indexing rather than partition projections.
AWS Glue partition indexing
Partition indexing is an alternative to partition projections that enables operation on a subset of partitions based on the search expression. The index is built consistently as partitions are added to the table through the AWS Glue Crawler or DDL. Like partition projections, this results in a reduced query time and also limits the amount of data scanned, but is typically better suited to highly-partitioned data at scale.
Partition indexing supports millions of partitions, reduces query time, reduces data transfers, and includes automatic index updates as partitions are added (as Glue table partitions are updated), making it suitable in many scenarios where your data set is high volume and highly partitioned. Up to three indexes can be added to a table to account for query patterns.
Review the AWS service limitations documentation to better understand if partition indexing is suitable for your use case. Both partition projection and partition indexing are compatible with Federated Search For Amazon S3.
Searching partitioned datasets
Let's look at a new example using AWS CloudTrail data. The table below contains information about the dataset that will be used to visualize the impact of executing searches against Glue tables representing a dataset partitioned by region and date.
The dataset uses S3 folder structure s3://mybucket/AWSLogs/123123789123/CloudTrail/${region}/${date}.
| Bucket path | Events | Volume |
|---|---|---|
|
Total eu-west-1 eu-west-1/2022/11/xx: eu-west-1/2022/12/xx |
1,998,549 events 1,108,409 events890,140 events |
~423MB ~223MB ~200MB |
|
Total us-east-1 us-east-1/2023/08/xx |
372,315 events | ~58MB |
|
Total us-west-1 us-west-1/2023/08/xx |
8,379 events 8,379 events |
~2MB ~2MB |
| All events | 2,379,243 |
Glue table definition
Let's continue using partition projections in this example, but note that the Splunk configuration and search results would still be similar if you were using partition indexing. In the TBLPROPERTIES below, two projections have been created - one for the AWS regions, and another for the date partitions. The storage template configuration defines how the projection values are substituted.
TBLPROPERTIES (
'projection.enabled'='true',
"projection.region.type"="enum",
"projection.region.values"="eu-west-1, us-east1, us-west-1",
'projection.date.format'='yyyy/MM/dd',
'projection.date.interval'='1',
'projection.date.interval.unit'='DAYS',
'projection.date.range'='2017/01/01,NOW',
'projection.date.type'='date',
'storage.location.template'='s3://mybucket/AWSLogs/123456789123/CloudTrail/${region}/${date}’
)
Splunk federated index partition time settings
Steps for configuring a federated provider and federated index are available in the Splunk Federated Search for S3 documentation and are not reproduced here; however, the Partition time settings values for the federated index must be configured to enable the date picker functionality in the UI.
Please note that the partition time settings shown in this example are specific to this example. In the DDL projection configuration above, the date partition configuration is expected in YYYY/MM/dd format. The time format in the Partition time settings should match the configuration using the Splunk date and time format variables.

Examples of data scanned when searching a partitioned dataset
Let’s explore how use of search partitions impacts your federated search for S3 searches from the Splunk platform.
Scenario 1: Scanning all events
In this first example, an all time count search is run for the entire federated index. In the screenshot you can see it returns a count of 2,379,243 events, which matches the number of events in the sample data.

The searchTelemetry details in the Search Job Inspector show the amount of data scanned and search execution. In this initial search, 506MB was scanned in 17.377 seconds.

Scenario 2: Adding a search term to limit results, but no reduction in scanned data
In this second scenario, the data is filtered on the awsregion field in the results, which also corresponds to the fourth segment value in the object path. This shows that similar fields in your data will result in filtration of results to the 372,315 events in us-east-1 as you’d expect, but there is no change to the amount of data scanned to return the results. Remember that the data is partitioned by region and not awsregion. The awsregion is a field in the event.

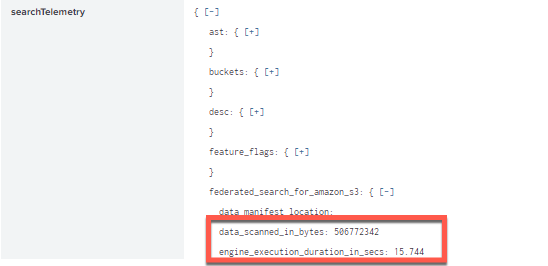
In the searchTelemetry, you can see that the scanned data in bytes is still approximately 506MB and the search execution took 15.7 seconds, so all the data was still scanned to bring back the results.
Scenario 3: Using the date picker to reduce scanned data
In this third search, the entire month of August was selected using the date picker. The same result count of 372,311 is returned, but this time the amount of data scanned was approximately 63MB in 5.7 seconds. This represents the data in the us-east-1 and us-west-1 buckets, since those are the only buckets with a partition aligned to August 2023.

Scenario 4: Using the date picker with the region partition
In this final search, the partition filters are combined with the region and date. The same number of results are returned in the count, but even less data was scanned to return the results.

Next steps
The examples in this article are intentionally simple and the data volumes are trivial. There are important limitations that you should familiarize yourself with before attempting to implement these concepts at scale. The documentation on partitioning data and partition projection from Amazon, as well as the Splunk Federated Search for Amazon S3, is a good starting point.
In addition, these resources might help you understand and implement this guidance: