Using federated search for Amazon S3 to filter, enrich, and retrieve data from Amazon S3
In this article, we’ll explore a compliance use case to access and retrieve unfiltered, raw data stored in Amazon S3 for compliance and long-term retention. As an admin, you might need to redact sensitive information from your application logs and enrich events with additional tags. A common next step is to then send the processed data to Splunk Cloud Platform indexes.
Using Splunk federated search for Amazon S3, however, admins can search and retrieve full raw datasets from Amazon S3 for compliance audits or in-depth analysis without storing all data in Splunk Cloud Platform. This capability optimizes both storage and costs. Admins can also perform lookups on historical data, enrich events with tags, and route them to multiple indexes in Splunk Cloud Platform.
This process involves the following steps:
- Create a pipeline to filter data using Splunk Edge Processor
- Route filtered data to Splunk Cloud Platform, and unfiltered data to Amazon S3
- Search data in your Splunk index to verify the pipeline
- (Optional) Perform data enrichment using Splunk Edge Processor via a lookup with KV Store
- Run a federated search for Amazon S3 to retrieve raw data stored in Amazon S3
Solution
Splunk Federated Search for Amazon S3 (FS-S3) allows you to search your data in Amazon S3 buckets directly from Splunk Cloud Platform without the need to ingest it. Edge Processor (EP) and Ingest Processor (IP) are Splunk features and products that offer the capability to route data to customer-managed Amazon S3 buckets.
Data required
This use case demonstrates how to perform this process with Cisco ASA data, however, this use case is applicable to other application data of your choice.
Prerequisites
Ensure you are familiar with Amazon S3, AWS Glue, Amazon Athena, Splunk Edge Processor and Ingest Processor, and Splunk federated search for Amazon S3. If any of these topics are not familiar, consider taking a few minutes to review them or make sure the documentation is handy. You can also find additional information about partitioning in the article Partitioning data in S3 for the best FS-S3 experience.
Edge Processor pipelines support Search Processing Language 2 (SPL2). If the SPL2 syntax is new to you, review the SPL2 Search Reference documentation.
Process
Create pipelines in Splunk Edge Processor to filter and route Cisco ASA data
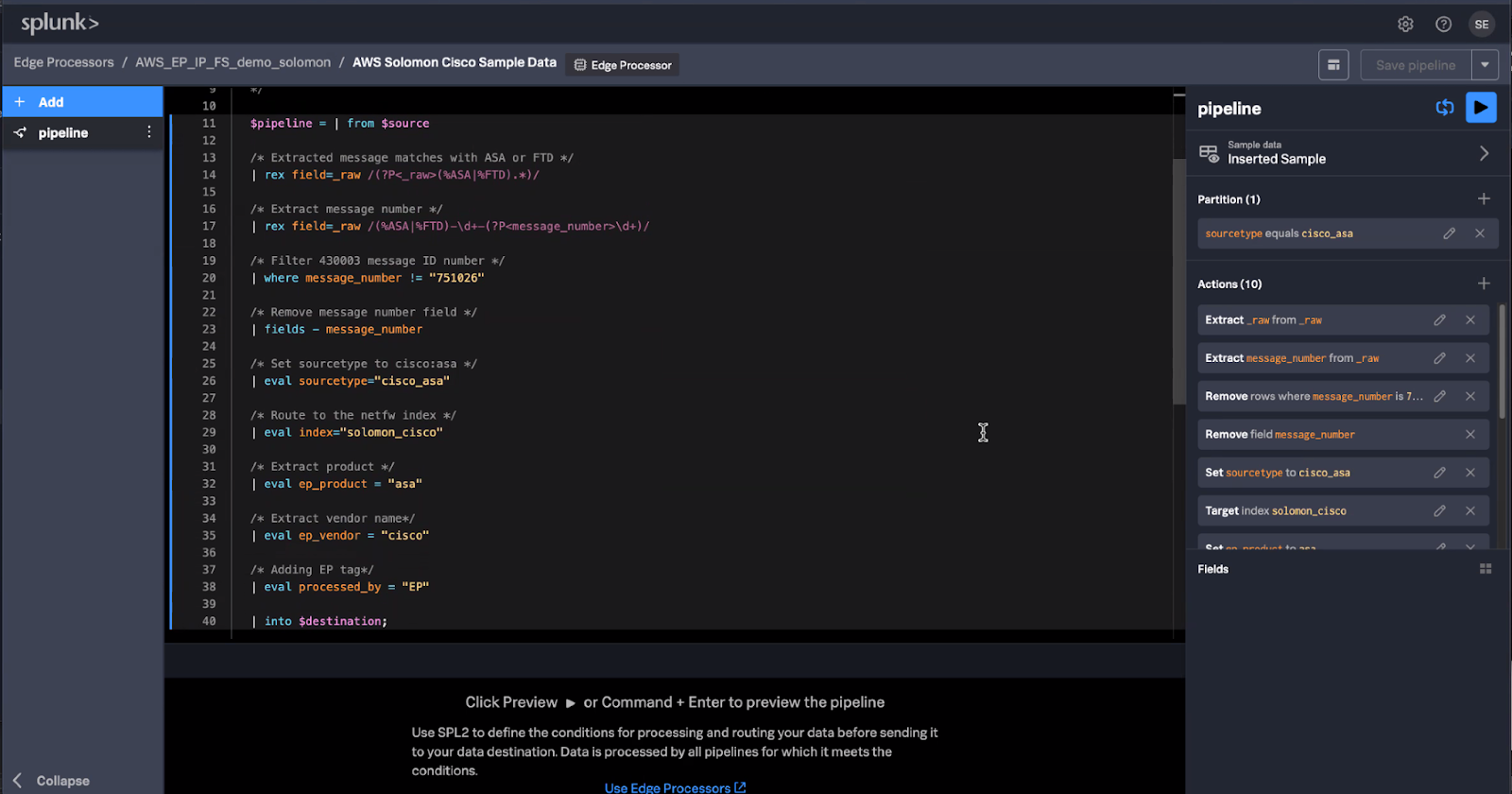
Pipeline 1: Filter Cisco ASA data and route to Splunk Cloud Platform
This Edge Processor pipeline takes the data and filters messages with the “751026” error code from Cisco ASA data. After filtering, the pipeline then sends the processed data to a Splunk index in Splunk Cloud Platform.
| Pipeline definition (SPL2) | $source |
|---|---|
|
|
|
This is what the final pipeline will look like:
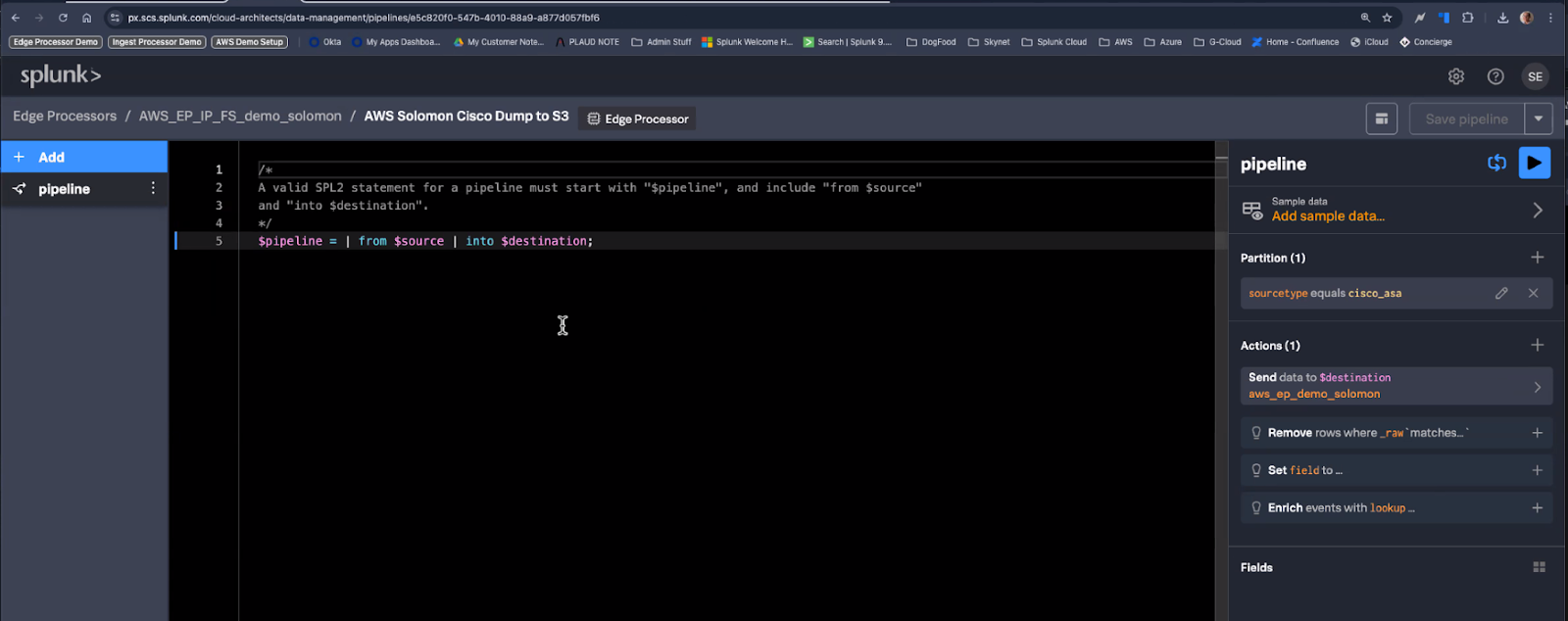
Pipeline 2: Route unfiltered copy of all Cisco ASA data to Amazon S3
This pipeline takes the raw data and routes it directly to Amazon S3 without touching it.
| Pipeline definition (SPL2) | $source |
|---|---|
|
|
|
This is what the final pipeline looks like:
After you have constructed your pipeline using the SPL2 above, follow these instructions to save and apply your pipeline.
- Test your pipeline rule. Click the blue Preview button in the top right corner of the screen.
- Set the Data destination to the appropriate index.
- Click Apply to save the destination.
- Click Save pipeline in the top right corner of the screen.
- Give your pipeline a suitable name, such as
cisco_asa_s3_<yourName>. - Click Save to save your pipeline.
- To try out the new pipeline, click Pipelines on the top left of the page.
- Locate the pipeline you just created, click the three dots next to your new pipeline, and select Apply/remove.
- Select the Edge Processor you created earlier and click Save. You will see a brief message stating that your changes are being saved.
Search data in your Splunk index to verify the pipeline
You can now verify that the pipeline has successfully been applied:
- Log into your Splunk Cloud Platform instance and open the Search app.
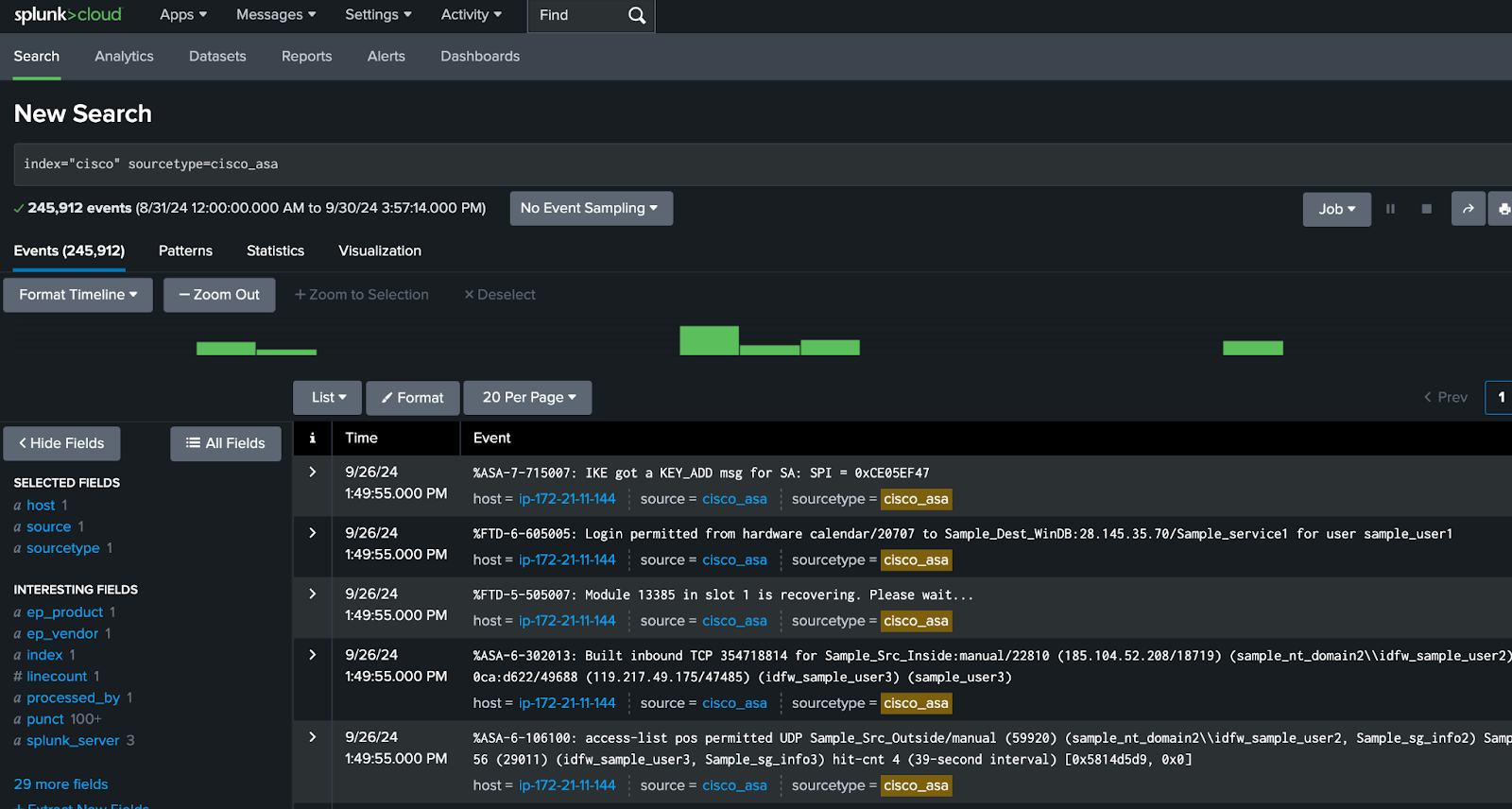
- Run the following search over any period you choose and verify that you can see the events coming from this pipeline:
index=”cisco” sourcetype=cisco_asa -
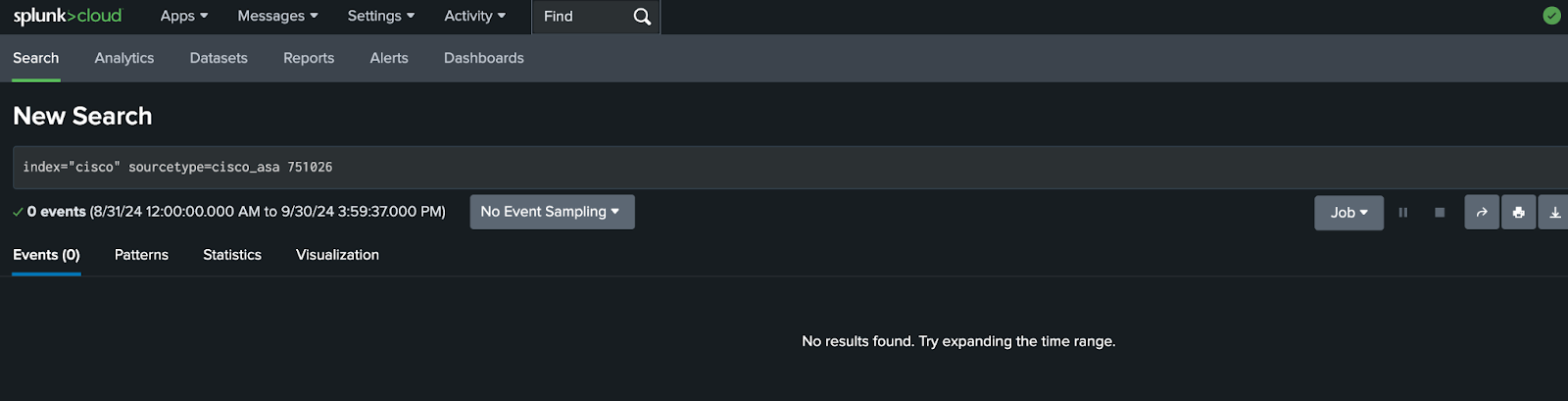
Search the same index with messages including “
751026” which should not return any results.index=”cisco” sourcetype=cisco_asa 751026
Optional: Perform data enrichment using Splunk Edge Processor via a lookup with KV Store
You can enrich your data by adding relevant information using a lookup. By creating and applying a pipeline that uses a lookup, you can configure an Edge Processor to add more information to the received data before sending that data to a destination. If you are unfamiliar with configuring KV Store lookups, refer to Configure KV tore lookups in Splunk Docs.
The key components to perform lookups are:
- KV Store: Allows users to store, retrieve, and manipulate structured data within the Splunk platform, using a key-value mechanism for efficient data handling. For more information, see About the app key value store.
lookup*: SPL command used to enrich event data by matching and adding fields from external data sources, such as CSV files or databases. For more information, see Search reference: lookup.
The general steps to enrich data with lookups using an Edge Processor are:
- Create a lookup in the pair-connected Splunk Cloud Platform deployment.
- Confirm the availability of the lookup dataset.
- Create a pipeline.
- Configure your pipeline to enrich event data using a lookup.
- Save and apply your pipeline.
For more detailed instructions, follow the steps in Enrich data with lookups using an Edge Processor or in Enriching data via real-time threat detection with KV Store lookups in Edge Processor.
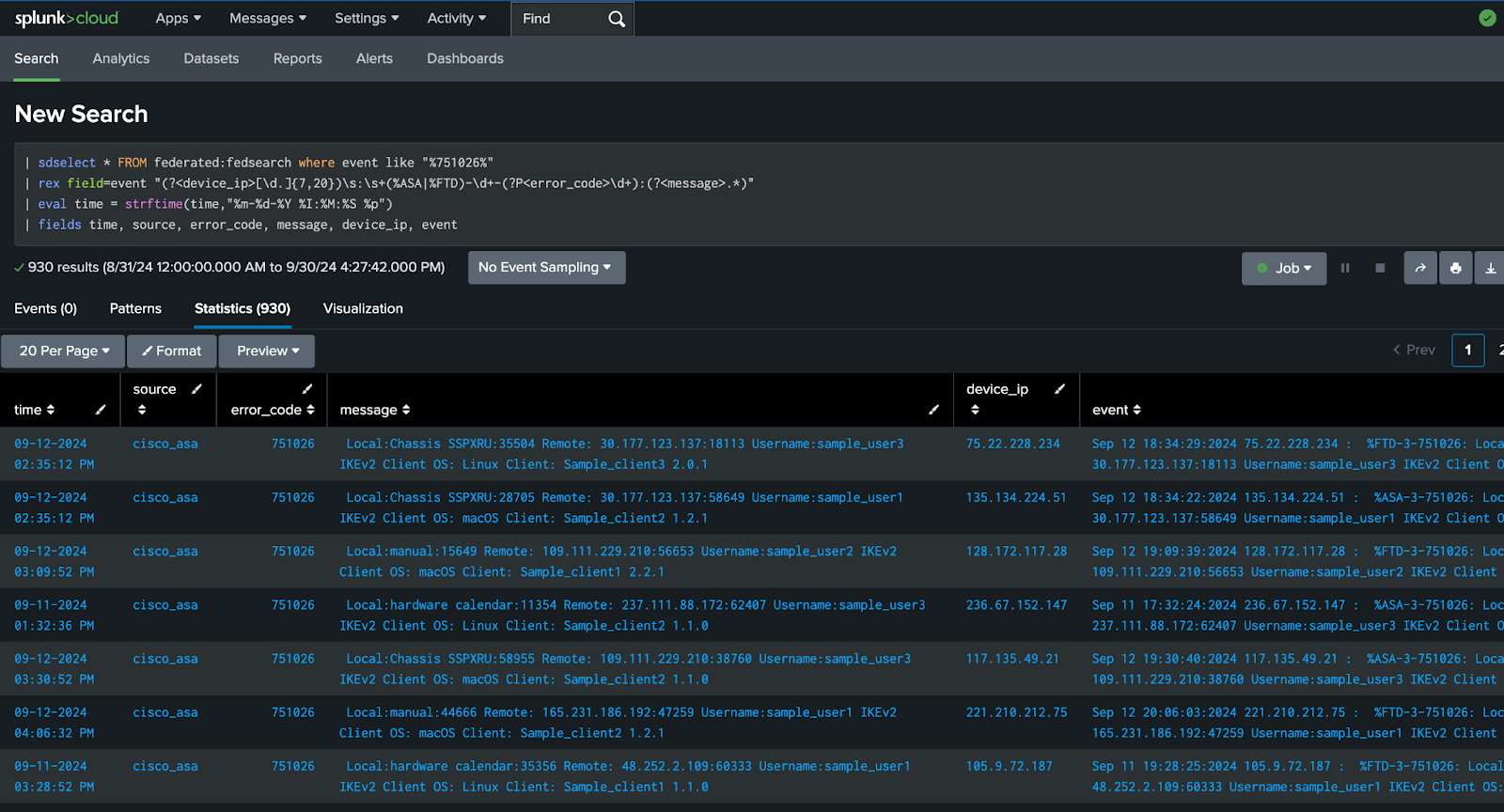
Run a federated search for Amazon S3 to retrieve raw data stored in Amazon S3
When you search for the raw, untouched Cisco ASA data routed to Amazon S3 for compliance, you can run a federated search for Amazon S3. To run the federated search, you can use the sdselect command with 751026 directly from the Search app in Splunk Cloud Platform.
| sdselect * FROM federated:fedsearch where event like "%751026%"
| rex field=event "(?<device_ip>[\d.]{7,20})\s:\s+(%ASA|%FTD)-\d+-(?P<error_code>\d+):(?<message>.*)"
| eval time = strftime(time,"%m-%d-%Y %I:%M:%S %p")
| fields time, source, error_code, message, device_ip, event
Next steps
These resources might help you understand and implement this guidance:
- Splunk Lantern: Partitioning data in S3 for the best FS-S3 experience
- Splunk Lantern: Using federated search for Amazon S3 (FS-S3) with Edge Processor
- Splunk Lantern: Using federated search for Amazon S3 (FS-S3) with ingest actions
- Splunk Docs: Use ingest actions to improve the data input process
- Splunk Docs: About Federated Search for Amazon S3
- Splunk OnDemand Services: Use these credit-based services for direct access to Splunk technical consultants with a variety of technical services from a pre-defined catalog. Most customers have OnDemand Services per their license support plan. Engage the ODS team at ondemand@splunk.com if you would like assistance.