Using federated search for Amazon S3 with ingest actions
Splunk federated search for Amazon S3 (FS-S3) allows you to search data in your Amazon S3 buckets directly from Splunk Cloud Platform without the need to ingest it. Ingest actions (IA), Edge Processor (EP), and Ingest Processor (IP) (in preview) are Splunk components that allow you to route data to your own managed Amazon S3 buckets.
EP, IP, and IA all partition data sent to S3 based on date; however, ingest actions also allow partitioning data by source type. While partitioning by date and source type are effective partitioning keys, the ingest actions docs state:
You can also set source type as a secondary key. However, if you are using federated search for Amazon S3 with the AWS Glue Data Catalog integration, you need to make sure that your Glue Data Catalog tables do not include a duplicate entry for the sourcetype column.
The warning in the statement is clear - make sure you don't have duplicate source types in the Glue table metadata. However, if you are new to routing data to S3 and federated search for S3, it might not be obvious how this might occur or what the implications of failing to deal with this duplication are. This article explores both of these ideas further.
The duplicate source type condition only exists with the JSON or new line delimited JSON (default) output format options, and does not occur when routing using the raw output format.
Prerequisites
You should ensure you are familiar with Amazon S3, AWS Glue, Amazon Athena, Splunk’s ingest actions, and Splunk’s federated search for Amazon S3. If any of these topics are not familiar, consider taking a few minutes to review them or make sure the documentation is handy. You can also find additional information about partitioning in the article Partitioning data in S3 for the best FS-S3 experience.
Ingest actions partitioning configuration
Let’s take a look at the partitioning portion of the IA destination configuration in the Splunk platform. Both of the images below show partitioning by the default schema of date using year, month, and day. This offers the greatest granularity and greatest ability to limit data scans, minimizing license consumption. In the image below, the provided sample path shows how the data is stored with the default Day option selected and the Partition by sourcetype as secondary key checkbox unchecked.

In the image below, the Partition by sourcetype as secondary key checkbox is checked. The provided sample path includes partitions by year, month, and day, and also includes a partition for source type after the date.

IA supports the use of an optional prefix prior to the year key that might be useful in reuse of a bucket for multiple subsets of data, applying different partition schemes, and supporting individual Amazon S3 lifecycle rules.
While including source type provides another level of granularity in your partitioning, with the potential to further limit data scans and license consumption, it also introduces a potential conflict when using federated search for S3 in the AWS Glue table metadata when using the AWS Glue crawler. The reason for this and the work around is explained below.
Demonstrating the problem
The S3 structure and the Glue table definition in the screenshot below shows what you'd expect to see after completing the IA configuration to send data to S3 and running the AWS Glue crawler.
In S3, the objects are being delivered to the path you'd anticipate based on the configuration, with the source type defined in the path. For example:
s3://my-bucket-name/year=2024/month=04/day=05/sourcetype=syslog/events_1712337421_1712337421_1712337452_000000_GUID.ndjson.gz
However, the source type is also defined in each event sent to S3. For example:
{
“time”:”<epoch time>”,
“event”:”<event string>”,
“host”:”<host>”,
“source”:”<source>”,
“sourcetype”:”<sourcetype>
}
Inspecting the AWS Glue table definition shows that the Glue crawler has created the source type column twice, finding the source type defined once in the event itself inside of the file (object in S3) and once from the partition (path of the object).
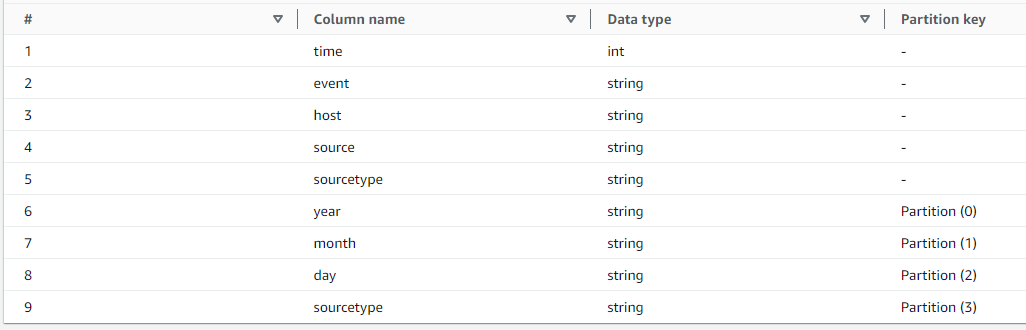
This is a problem because FS-S3 will find duplicate information and will not know which source type to use. To demonstrate the problem with the column definition existing twice, we can query the table with FS-S3. The query results in the following error visible from the Splunk UI:
The Federated Search for Amazon S3 client failed to run the search. It encountered the following error: Failed to run search, state=FAILED, reason="hive_invalid_metadata: hive metadata for table <table name> is invalid: table descriptor contains duplicate columns"
Solving the problem
With the root of the duplication and issue identified, let's review two different ways to resolve this problem
Edit the glue table schema
If the Glue table has been defined using the Glue crawler, there are two actions that are required to resolve this problem.
- In the Glue crawler’s Set output and scheduling configuration screen, expand the Advanced options and do the following:
- Select Ignore the change and don’t update the table in the data catalog.
- Select Update all new and existing partitions with metadata from the table.
- Select Create partition indexes automatically.
- Edit the schema for the Glue table and delete the source type column that is not defined as a partition.
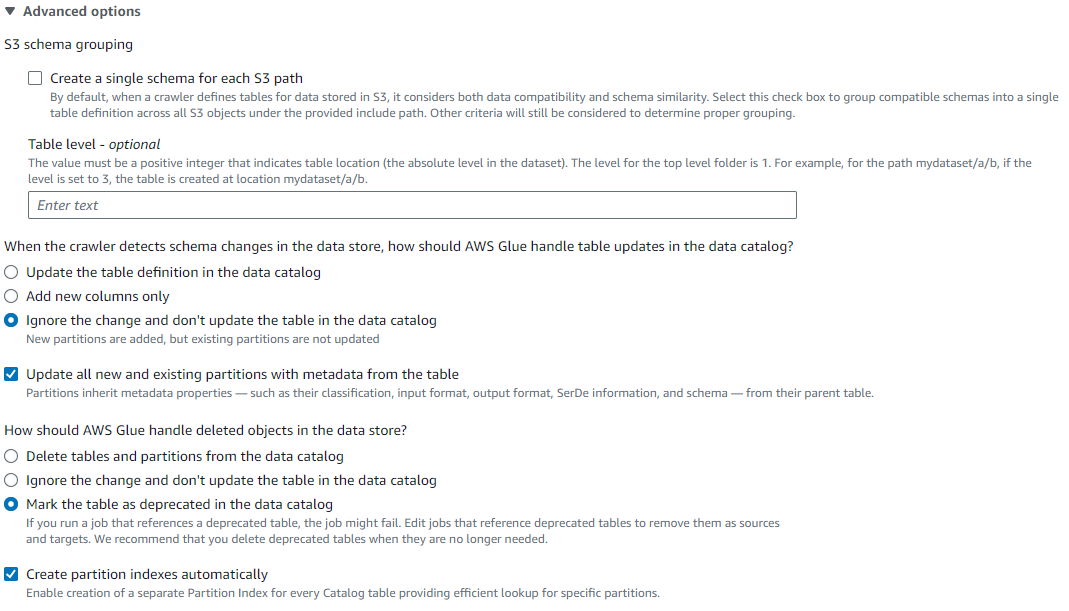
After updating these settings, the table should be queryable.
The Glue crawler should be enabled to run on a schedule to ensure that new partitions are added. The schedule should align with partition creation. In the case of ingest actions, partitions are created daily as new events are written, so scheduling the crawler to align with the creation of the new partitions ensures they are promptly detected and included in future searches.
Define the table using Data Definition Language
Alternatively, it is possible to define the table using Data Definition Language (DDL) in Athena without using the Glue crawler at all. Manually creating the table definition allows complete control over the table, including partitions. The sample Athena query below shows how Glue table columns and partitions can be defined using DDL.
CREATE EXTERNAL TABLE `my_table_name`( `time` double, `event` string, `host` string, `source` string) PARTITIONED BY ( `year` string, `month` string, `day` string, `sourcetype` string)
As with the Glue crawler, sourcetype must also be omitted in the table column definition portion of the DDL to prevent a conflict with the source type statement shown in the PARTITIONED BY section.
When new partitions are created by IA, they must also be created in the table metadata. You can do this using the ALTER TABLE statement below.
ALTER TABLE <REPLACE-NAME> ADD PARTITION (year = 'REPLACE', month = 'REPLACE', day=REPLACE', sourcetype='REPLACE');
Unlike the Glue crawler with built-in scheduling, you'll need to implement a solution to update the table metadata as partitions are created. You can either:
- make the configuration changes to the Glue crawler
- manually create a Glue table using DDL to produce a table definition that will be queryable by federated search for S3, even when partitioning based on source type in addition to date
Creating a table in the AWS Glue catalog
The schema implemented by IA can be parsed with the Glue crawler. Modifications might be necessary, but the crawler provides a starting point. The DDL table creation method requires familiarity with DDL statements, but this is a fairly straightforward definition for data sent to S3 using IA. Unless you need to use DDL for partition projections, use whichever approach you are most comfortable with to create your AWS Glue tables.
Index-time fields
Index-time fields in the JSON payload might be defined as searchable columns by the AWS Glue crawler or by DDL, and these fields are searchable in FS-S3 queries. Data sent to Amazon S3 with IA is written using the HEC format, and the default configuration in IA for output fields are ingest actions default and custom index-time fields, so unless you do not want your fields to be searchable you can move forward with the defaults.

Define your index-time fields like this. Note the `sourcetype` field is not present:
{
“time”:”<epoch time>”,
“event”:”<event string>”,
“host”:”<host>”,
“source”:”<source>”,
“Fields”: {
“<indextimefieldx>”: “<value>”,
“<indextimefieldy>”: “<value>”,
“<indextimefieldz>”: “<value>”
}
}
Timestamp format
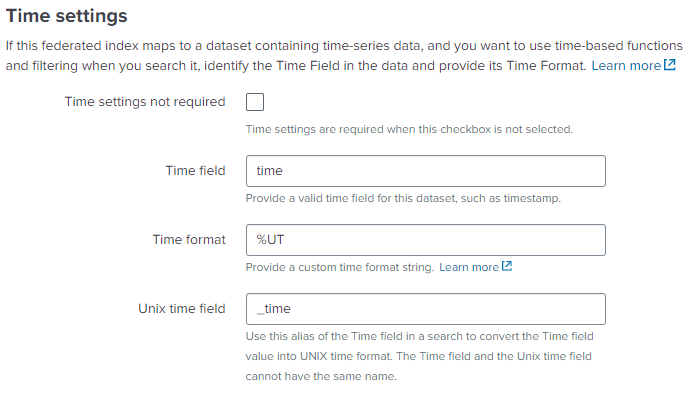
The federated index definition requires use of time format in the Time settings configuration that are not part of the standard Splunk platform time format variables. The AWS Glue tables for data written by IA should create a time column by default and use the double data type. You'll need to use the %UT time format with the numeric double data type.
%sfor UNIX time values in string data type.%UTfor UNIX time values in numeric data type.%STfor values in SQL timestamp data type.
File size
Small objects increase the overhead associated with compression, opening, and transferring objects. By default, IA defaults to a 128MB buffer size for objects before writing to S3. While this parameter may be tuned to meet use case requirements, modifying the default value to a value smaller than 128MB may have a significant negative impact on FS-S3 performance. Conversely, significantly increasing this value increases latency with writes to S3.
Service limits
When planning your architecture, you'll need to consider service limits. Review the latest ingest actions and federated search for S3 documentation for the latest service limits.
Next steps
There are important limitations that you should familiarize yourself with before attempting to implement these concepts at scale. There are many technical details outside the scope of this article that might influence your decision making. Documentation for Federated Search for S3, Ingest Actions, and the Ingest Actions Splunk Validated Architecture (SVA) are a good starting point for expanding your knowledge past the concepts discussed in this article.
If you need additional technical implementation guidance, engage your Splunk and/or AWS account teams.