Splunk ソフトウェアによるエンタープライズ WAN サービスの保証
Cisco SD-WAN は、アプリケーションを認識するルーティングと一元化されたポリシーをエンタープライズ WAN アーキテクチャにもたらしました。しかし、それによって障害の表面も変わりました。従来のマルチプロトコルラベルスイッチング(MPLS)のみの設計では、通常、サイトがダウンするとリンクが物理的にダウンすることになります。SD-WAN では、双方向転送検出 (BFD) セッションタイムアウト、オーバーレイ管理プロトコル (OMP) ルートの撤回、トランスポートレベルの SLA クロッシング、または基盤となる WAN インターフェイスの障害によって同じ症状が発生することがあります。それぞれ異なる調査経路と異なる修復方法が必要です。
vManageコントローラ(最近はCisco SD-WAN Managerとしてブランド名が変更されました)により、デバイスの状態とポリシーアプリケーションを可視化できます。提供されていないのは、サービスレベルのビューです。つまり、どのサイトがどの程度影響を受けているか、どの程度深刻で、サイトからデバイス、インターフェイスまで WAN 階層全体で低下している原因は何かということです。Splunk ソフトウェアが提供するのは、このクロスレイヤーコンテキストです。
前提条件
ソフトウェア
この機能は、特定のSplunkアプリとCiscoテクニカルアドオンを組み合わせて構築されています。
- Acme SD-WAN オペレーションコマンド。これは Splunk Enterprise 上に構築されたプライベートアプリです。これは 架空の ACME ネットワーク用のカスタムダッシュボードセットで、以下の情報を得ることができます。 トンネルの安定性、アプリケーションパスステアリング、WAN インターフェースの状態 このアプリは一般公開されていませんが、この記事では、このユースケースを実現するためにSplunkプラットフォームで構築できる機能の力を紹介します。一部の検索の正確な SPL は、すぐに始められるように記載されています。環境に合わせた同様のアプリを構築するためのその他のヘルプは、以下を参照してください。 開発者向けドキュメンテーション またはとの契約 プロフェッショナルサービス 。
- シスコカタリストアドオン 。vManage コントローラデータ、デバイステレメトリ、トンネル SLA メトリック、統合脅威防御 (UTD) セキュリティイベント、およびシステムログを経由して取り込みます。 REST API の管理 。
- スプランクストリーム (vEdge/cEdge からのネットフロー)。混在するアプリケーション、東西とインターネットのトラフィック、まれなアプリケーション (シャドー IT) の検出など、きめ細かなフロー分析を行います。
- Splunk ITSI (ITSI)。SD-WAN テレメトリをサイトレベルのヘルススコアでサービスツリーにマッピングします。適応型閾値処理は、厳しい閾値に達する前に劣化を検出します。
テレメトリオンボーディング:コントローラー+デバイス+フロー
| データソース | インテグレーション/TA | Splunk ソースタイプ |
|---|---|---|
| サイトとデバイスの状態 | シスコ SD-WAN TA (REST API の管理) |
cisco:sdwan:sitehealth
|
| トンネル SLA メトリック | シスコ SD-WAN TA (REST API の管理) |
cisco:sdwan:tunnelhealth
|
| WAN リンクとインターフェイス | シスコ SD-WAN TA (REST API の管理) |
cisco:sdwan:linkhealth
|
| セキュリティサービスエッジ (SSE) トンネル状態 | シスコ SD-WAN TA (vManage REST API) |
cisco:sdwan:ssetunnels
|
| UTD の脅威とポリシー | シスコ SD-WAN TA (REST API の管理) |
cisco:sdwan:utd:logs
|
| システムイベントとコントロールイベント | シスコ SD-WAN TA (vManage REST API) |
cisco:sdwan:system:logs
|
| アプリケーションフローデータ | Splunk ストリーム (エッジからの NetFlow) |
stream:netflow
|
SD-WAN 運用のための重要な KPI
Splunk ITSI で KPI を設定して管理する方法については、以下を参照してください。 ITSI における KPI の作成の概要 。
| KPI | それが教えてくれること |
|---|---|
| サイトヘルススコア (サイトごと) |
から派生
cisco:sdwan:sitehealth
— トンネル、デバイス、およびアプリケーションの状態を、場所ごとに集計したもの。
|
| トンネル状態 (アップ/ダウン) |
cisco:sdwan:tunnelhealth
— トンネルごとの動作状態。ダウントンネルは、サイト間の接続に障害が発生していることを示します。
|
| トンネルパケットロス% |
cisco:sdwan:tunnelhealth
— トンネルごとのパケット損失。しきい値を超えると、SLA ベースのパススイッチングがトリガーされます。
|
| トンネル遅延 (ミリ秒) |
cisco:sdwan:tunnelhealth
— トンネルあたりのラウンドトリップ時間 (RTT)。ZoomやVoIPなどのレイテンシーの影響を受けやすいアプリケーションのパス選択を促進します。
|
| トンネルジッター (ミリ秒) |
cisco:sdwan:tunnelhealth
— パケット遅延変動。リアルタイムのアプリケーション品質にとって重要です。
|
| WAN インターフェイスの動作状態 |
cisco:sdwan:linkhealth
— インターフェイスごとのアップ/ダウン状態、速度、受信/送信 (RX/TX) kbps 使用率。
|
| BFD セッションステート |
cisco:sdwan:sitehealth
— BFD がダウンすると、トンネル障害が差し迫っているか進行中になります。
|
| OMP ピアステート |
cisco:sdwan:system:logs
— OMP セッションヘルス。損失により vSmart からのルート配信が中断されます。
|
| UTD 脅威イベント |
cisco:sdwan:utd:logs
— ブロック/許可されたアクション、脅威カテゴリ、レピュテーションスコア、シグネチャ ID
|
| まれなアプリケーション検出 |
stream:netflow
— エッジ全体にわたるまれなアプリケーションフロー分析によるシャドーIT識別。
|
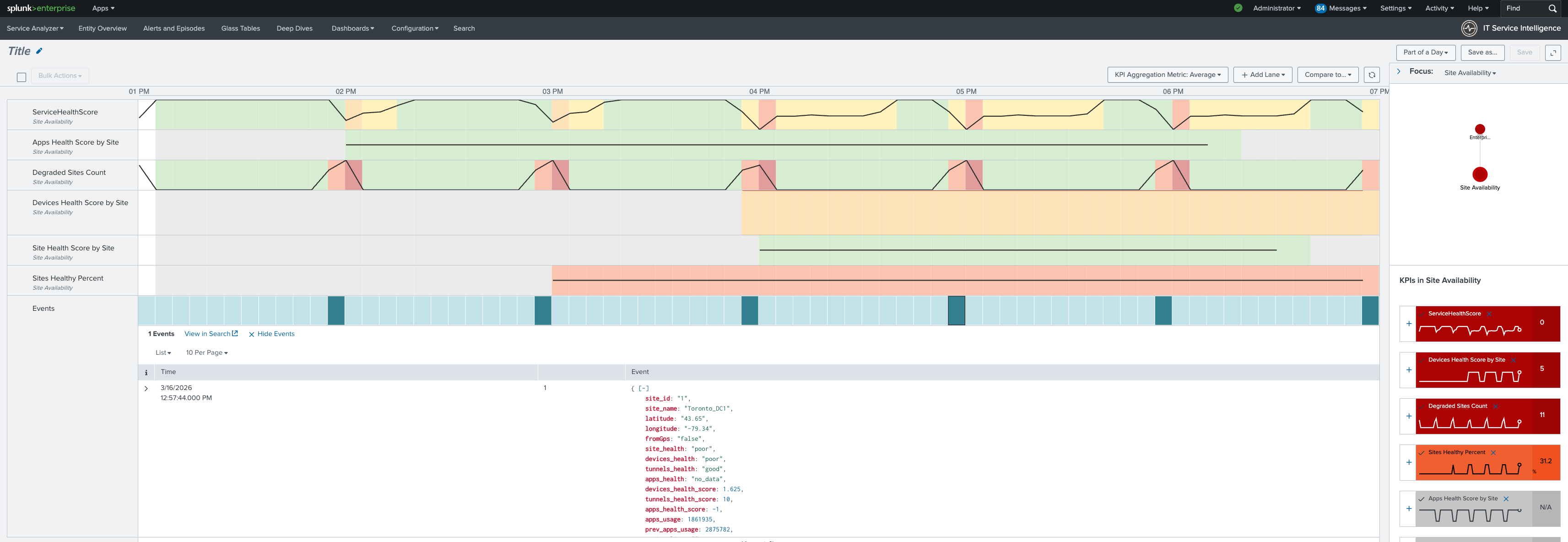
運用シナリオ:トロントハブの劣化
サービスビュー:スコープ (秒単位)
SD-WAN ファブリックの全用途を示す以下の ITSI ガラステーブル
cisco:sdwan:sitehealth
トロントの健康状態が悪化していることを明らかにするデータ。その他のサイト (オタワ、エドモントン、カルガリー、およびセキュアアクセスノード) はすべて緑色です。問題の範囲は、ドリルダウンを行う前に確認されます。10 サイトのファブリックの場合、vManage を使用して対象範囲を手動で確認するには、各サイトのデバイスリストを開いてトンネルの状態を個別に確認する必要があります。Splunk ソフトウェアでは、1 秒で確認できます。

次に、サービスアナライザーを詳しく調べて SD-WAN サービスを調べます。デバイスの状態とトンネルの状態が悪化していることがわかります。アプリケーションの状態も黄色です。この情報に基づくと、調査の焦点はエッジデバイスと WAN インターフェイスであるはずです。つまり、ポリシー構成と vManage の状態は原因から除外できるということです。

最後に、以下を使用してこの KPI タイムラインを確認してください。
cisco:sdwan:sitehealth
そして
cisco:sdwan:tunnelhealth
データソース。デバイスの状態が最初に低下し、次にトンネルの状態が低下したことがわかります。開始時のタイムスタンプは、変更の相関関係のタイムラインに表示されます。
オペレーション・コマンド・センター:インフラストラクチャー詳細
Splunk プラットフォームの運用コマンドセンターのメインダッシュボードには、サイトの稼働率、トンネルのダウン数、デバイスの可用性などの重要な情報が一目でわかります。トロントの劣化は、以下のすべての集計指標に反映されます。
cisco:sdwan:sitehealth
。

リンクとインターフェース:根本原因を確認
[リンクとインターフェイス] タブには、以下を使用して、エッジデバイスごとの WAN インターフェイスの物理状態が表示されます。
cisco:sdwan:linkhealth
。
- Toronto cEdge の複数のインターフェイスが動作停止しています。
- これらのパスの BFD セッションがタイムアウトしました。
- OMPはそれらのトンネルが通っていたルートを撤回しました。
インターフェイス障害からトンネルのドロップ、サイトの劣化に至るまでのカスケードは、CLI セッションを 1 回も実行しなくても完了し、エンドツーエンドで追跡できます。

調査の背後にあるSPL
オペレーション・コマンド・センターに表示したい情報は、デバイスやトポロジーによって異なります。含めたいと思われる検索例をいくつか示します。
目的 : ダウンストリームのトンネルのドロップに関連する WAN インターフェイス障害
index=sdwan sourcetype="cisco:sdwan:linkhealth"
| lookup sdwan_entities_master device_ip as vdevice-name
| fields vdevice-name if-oper-status if-admin-status ip-address speed-mbps vpn-id ifname details entity_type site
| stats
latest(if-admin-status) AS admin
latest(if-oper-status) AS oper
latest(ip-address) AS ip
latest(speed-mbps) AS speed
latest(vpn-id) AS vpn latest(details) AS device_detail latest(entity_type) AS device_role latest(site) AS site
BY vdevice-name ifname
| eval status_icon=case(
(admin="if-state-up" OR admin="Up") AND (oper="if-oper-state-ready" OR oper="Up"), "UP",
(admin="if-state-up" OR admin="Up") AND (oper="if-oper-state-down" OR oper="Down"), "DOWN",
admin="if-state-down" OR admin="down", "ADMIN_DOWN",
1=1, "UNKNOWN")
| where status_icon!="P"
| sort vdevice-name vpn ifname
| head 50
| table vdevice-name ifname status_icon admin oper ip speed vpn device_detail device_role site
目的 : トンネルヘルスサマリー — トンネルの可用性がしきい値を下回っているサイトを特定します
index=sdwan sourcetype="cisco:sdwan:tunnelhealth"
| fields _time name loss_percentage latency jitter state health local_color remote_color site_id
| stats latest(*) AS * BY name
| lookup site_name site_id AS site_id OUTPUT site_name
| eval
loss = round(coalesce(loss_percentage, 0), 2),
lat = round(coalesce(latency, 0), 2),
jit = round(coalesce(jitter, 0), 2),
path = local_color . " ↔ " . remote_color,
status_rank = case(
state != "Up", 1,
loss > 5 OR lat > 250, 2,
loss > 1 OR lat > 150 OR jit > 30, 3,
1=1, 4),
"SLA Status" = case(
status_rank == 1, "DOWN",
status_rank == 2, "SLA VIOLATION",
status_rank == 3, "SLA DEGRADED",
status_rank == 4, "OPERATIONAL")
| sort status_rank - loss
| table "SLA Status" site_name name path loss lat jit health
目的 : UTD 脅威アクティビティ — ブロックされたイベントをレピュテーションコンテキストで表示
index=sdwan sourcetype="cisco:sdwan:utd:logs"
| stats count BY src_ip dest_ip Category Reputation
| sort -count
| head 20
目的
: シャドウ IT 検出 — まれなアプリケーションが外部から流出
stream:netflow
index=netflow sourcetype="stream:netflow" src_ip=*
| eval application = coalesce(app, app_tag, "Unknown_Flow")
| eval application = trim(replace(application, "\x00", ""))
| stats
count AS pair_flow_count
BY application protoid src_ip dest_ip
| eventstats
avg(pair_flow_count) AS avg_flows
stdev(pair_flow_count) AS dev_flows
BY application
| where pair_flow_count < (avg_flows - dev_flows) OR pair_flow_count <= 2
| sort + pair_flow_count
| table application protoid src_ip dest_ip pair_flow_count avg_flows
調査の逆化:サービスから根本原因まで
vManage のトラブルシューティングはデバイスから始まります。アラートが発生しているデバイスを見つけ、サービスへの影響を把握するために作業を進めます。Splunk ソフトウェアはこれを逆にします。つまり、サービスから始め (トロントは劣化しています。ヘルススコアはここにあります)、原因となっているコンポーネント (デバイスの状態とトンネルの状態) を掘り下げて、デバイスレイヤーで根本原因を確認します。「リンクとインターフェース」タブにたどり着く頃には、探索しているわけではなく、確認していることになります。この逆転こそが、MTTR の改善の源です。
要約:NetFlow: アプリケーションインテリジェンスレイヤ
デバイスとトンネルのメトリック以外にも、
cisco:sdwan:system:logs
そして
stream:netflow
SD-WANの運用には、コントローラーのダッシュボードにはないビュー、つまりWANを流れる実際のアプリケーショントラフィックパターンが表示されます。帯域幅を最も多く使用しているのはどのアプリケーションか?Microsoft O365 トラフィックはダイレクトインターネットブレークアウトポリシーに従っているのか、それともデータセンターを経由してフォールバックしているのか?WAN の容量を消費するシャドウ IT ツールなど、ブランチエッジに予期しないアプリケーションが出現していませんか?
Splunkソフトウェアを使用すれば、このような疑問にSPLで回答できるようになります。
stream:netflow
データ。以下の UTD 脅威イベントと合わせて
cisco:sdwan:utd:logs
これにより、ネットワークチームとセキュリティチームの両方が、何がWANを通過しているか、またWANがポリシーに準拠しているかどうかを一元的に把握できます。
大規模なエンタープライズファブリックを管理するSD-WAN運用チームにとって、これは、同じプラットフォーム内のNetOpsとSecOpsのギャップを埋めるためのセキュリティコンテキストを備えた事後対応型のアラート主導型モデルを、セキュリティコンテキストを備えたプロアクティブなサービス主導型モデルに変える運用レイヤーです。
次のステップ
組織におけるネットワークアシュアランスの提供について詳しく知る準備はできていますか?このシリーズの他の記事もご覧ください。