Using Kubernetes Horizontal Pod Autoscaling
In a Kubernetes environment you can scale your application up or down with a command, a UI, or automatically with autoscalers. However, to scale effectively, it's important to understand when you're reaching scaling limits and whether your scaling efforts are successful. Without this insight, you might continue to use resources inefficiently or encounter application performance issues unnecessarily.
This article explores Kubernetes Horizontal Pod Autoscaling (HPA), when you might use HPA, caveats you might hit when scaling pods, and how you can use Splunk Observability Cloud to gain insight into your Kubernetes environment to ensure you’re scaling efficiently and effectively.
Data required
Kubernetes Autoscaling
Autoscaling is a good way to increase the capacity of your Kubernetes environment to match application resource demands with minimal manual intervention. With autoscaling, resources automatically adjust based on varying demand. This creates a more elastic, more performant, and more efficient (both in terms of application resource consumption and infrastructure costs) Kubernetes environment.
Kubernetes supports both vertical and horizontal scaling. Vertical (up/down) scaling adjusts resources like memory and CPU within an existing workload (for example, increasing or decreasing memory for a running process). Horizontal (in/out) scaling adjusts the number of replicas (for example, increasing or decreasing the number of instances). Vertical scaling is ideal for right-sizing Kubernetes workloads to ensure they have the necessary resources, while horizontal scaling is ideal for dynamically responding to unexpected bursts or busts in traffic by distributing the load.
Horizontal and vertical autoscaling can be configured at the cluster or pod level using Cluster Autoscaling, Vertical Pod Autoscaling, or Horizontal Pod Autoscaling. Since the Horizontal Pod Autoscaler (HPA) is the only autoscaler included by default with Kubernetes, we will focus on HPA.
Horizontal Pod Autoscaling
To scale a Kubernetes workload resource like Deployments or StatefulSets based on the current demand of resources, you can either scale workloads manually or automate the process through autoscaling. Automatically scaling up or down to match demand reduces the need for manual intervention and ensures efficient resource use within your Kubernetes infrastructure. If load increases, horizontal scaling will respond by deploying more pods. Conversely, if load decreases, the HorizontalPodAutoscaler will instruct the workload resources to scale down, as long as the number of pods is above the configured minimum.
Horizontal Pod Autoscaling considerations
Automatically scaling pods is a hugely beneficial feature of Kubernetes, but there are some caveats when implementing Horizontal Pod Autoscaling. Here are some things to be aware of:
- Metric lag: The HorizontalPodAutoscaler continuously checks the Metrics API for resource usage to inform scaling behavior, which can introduce a lag between monitoring usage and scaling. By default, HPA checks metrics every 15 seconds.
- Vertical scaling conflicts: Vertical Pod Autoscaling (VPA) and HPA should not be used together based on the same metrics, as this can lead to conflicting scaling decisions.
- Resource limits: If requests and limits are not properly configured, HPA might not be able to scale out. Fine-tuning these thresholds can be tricky and requires careful monitoring of resource limits.
- Resource competition: New pods can compete for resources and can take time to initialize and stabilize.
- Application compatibility: Not all applications can easily scale horizontally (for example, single-threaded applications, those with order-dependent queues, or databases). Ensure your application is compatible before implementing HPA.
- DaemonSets: HPA does not apply to DaemonSets. To scale DaemonSets, consider scaling the node pool instead.
- Dependency bottlenecks: External dependencies (for example, third-party APIs) may not scale at the same rate, or at all, so plan to scale those as needed.
Implementing HPA
Now that we know what Horizontal Pod Autoscaling is and some things to be aware of when working with HPA, let’s see it in action.
We have a PHP/Apache Kubernetes deployment under the Apache namespace that is exporting OpenTelemetry data to Splunk Observability Cloud. Our deployment creates a new StatefulSet with a single replica. We'll start by exploring the Splunk Observability Cloud Kubernetes Navigator.
In the Navigator, by filtering down to our cluster and the Apache namespace, we can see that we currently only have one pod in our node.

The pod is receiving some significant load, and for the purposes of this example, we have deliberately limited the resources for each Apache pod. We can see spikes in CPU and memory usage that are leading to insufficient resources.


These spikes are causing containers to enter a CrashLoopBackOff state. We might see that we have one active container.

Then suddenly, that container will crash and we’ll have zero active containers before it attempts to restart again.
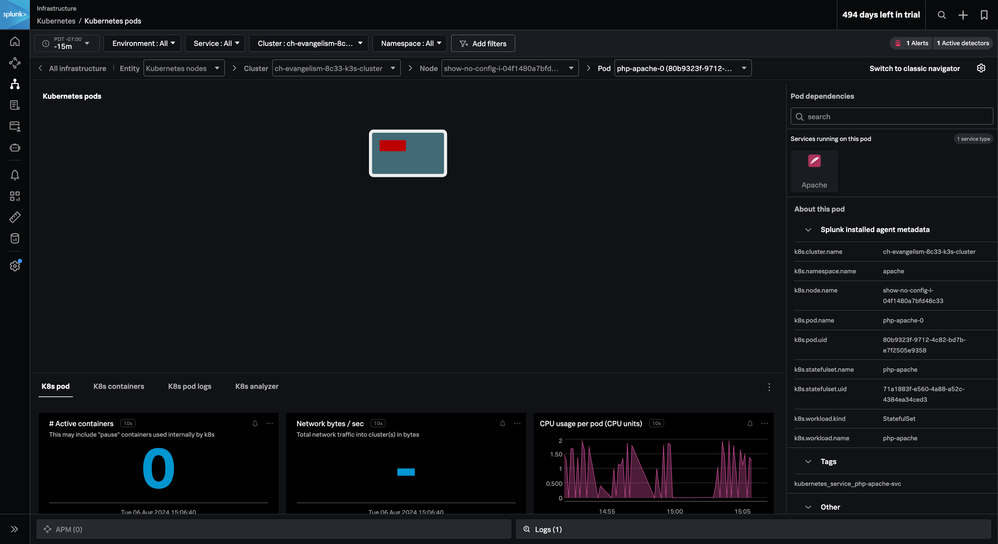
Not only can we see these containers starting and stopping in real-time, but the restarts triggered an AutoDetect detector that would have notified our team of an issue.

The Kubernetes Navigator has helped us identify resource issues and the impacts they’re having on containers. Now, we need to resolve these issues by setting up Horizontal Pod Autoscaling so the workload will automatically respond to this increased load and scale out by deploying more pods.
First, create an HPA configuration file under the ~/workshop/k3s/hpa.yaml directory. An example config file is shown below, however you'll need to adjust fields such as name and namespace to fit your environment.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: apache
spec:
maxReplicas: 4
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
- type: Resource
resource:
name: memory
target:
averageUtilization: 75
type: Utilization
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: StatefulSet
name: php-apache
The HorizontalPodAutoscaler object specifies the behavior of the autoscaler, allowing control over resource utilization, setting the minimum and maximum number of replicas, specifying the direction of scaling (up/down), and setting target resources to scale. We apply the configuration by running kubectl apply -f ~/workshop/k3s/hpa.yaml.
We can verify that the autoscaler was created and validate Horizontal Pod Autoscaling with the kubectl get hpa -n apache command. Here’s what the response looks like:

Now that HPA is deployed, our php-apache service will autoscale when either the average CPU usage goes above 50 percent or the average memory usage for the deployment goes above 75 percent with a minimum of one pod and maximum of four pods. In the Kubernetes Navigator nodes view, we can validate that we now have four pods to handle the increased load. We’ve added a filter to highlight the four pods in the Apache namespace:
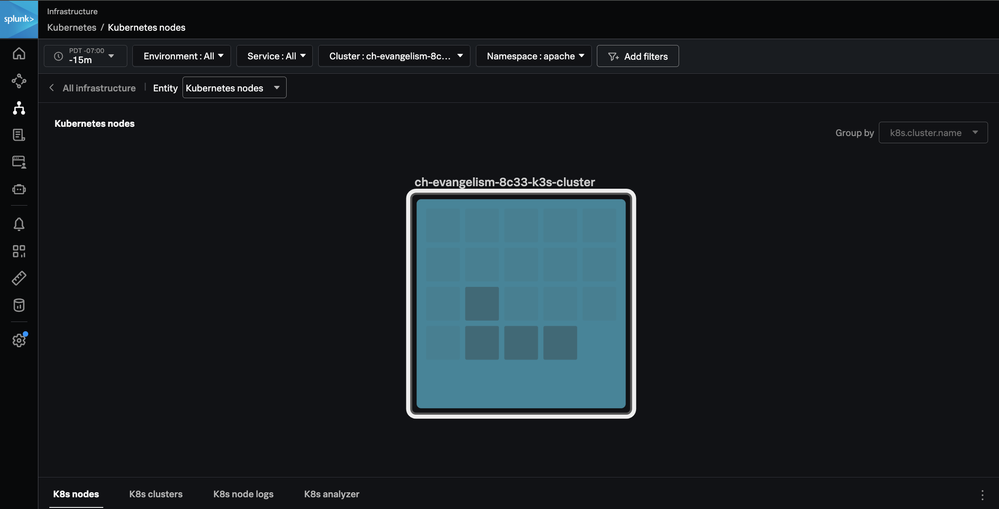
In the K8s pods tab, we can see additional pod-level metrics and again verify the number of active pods is now four.

If we wanted to increase the number of pods to eight, we could update our hpa.yaml and specify eight maxReplicas. After that configuration is deployed, we can see we now have eight active Apache pods:
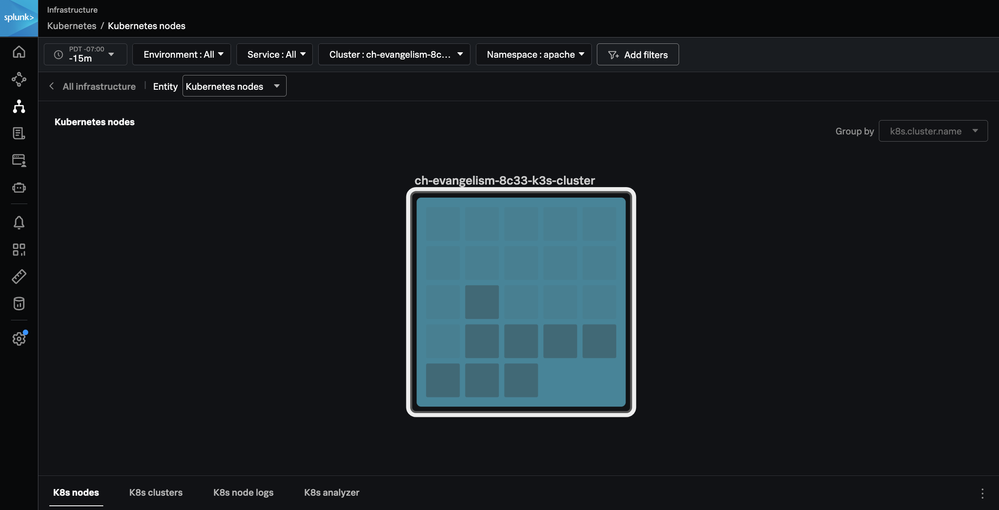
After configuring the Horizontal Pod Autoscaler, we can watch our container count remain steady as our pods autoscale to handle the increased traffic.
Next steps
These additional resources might help you understand and implement this guidance:
- Splunk Lantern Article: Detecting and resolving issues in a Kubernetes environment
- Splunk Resource: Introduction to K8s Horizontal Pod Autoscaling