Prescriptive Adoption Motion - Data sources and normalization
Splunk Enterprise Security works most effectively when you send all your security data into a Splunk deployment to be indexed. You should then use data models to map your data to common fields with the same name so that they can be used and identified properly.
The volume, type and number of data sources influence the overall Splunk platform architecture, the number and placement of forwarders, estimated load, and impact on network resources. The Splunk platform can index any kind of data, for example, IT streaming, machine, and historical data, such as Microsoft Windows event logs, web server logs, live application logs, network feeds, metrics, change monitoring, message queues, or archive files.
Getting Data In (GDI) is the process that you'll follow to ingest machine data into the Splunk platform. Correct data ingestion produces many benefits that make implementing other solutions easier. It allows your team to focus on the analysis and prioritization tasks that are most important to your organization.
The information in this article applies to Splunk Enterprise Security (ES) versions 7.x. If you have upgraded to Splunk Enterprise Security version 8.x, some terminology and steps might not apply. For additional assistance on this use case with ES 8.x, Splunk Professional Services can help.
Aim and strategy
Data normalization helps to match your data to a common standard by using the same field names and event tags for equivalent events from different sources or vendors. This is hugely beneficial when it comes to combing through data from multiple sources.
Another goal of normalization is to present a unified view of a data domain using reports, correlation searches, or dashboards.
The benefits of data normalization include:
- Reliable and consistent format of data
- Easier to implement alerts and correlation rules
- Easier to implement apps and add-ons
- Increased confidence and data integrity
Common use cases
Using data models for more efficient correlation rules and searches
SOC Engineers or Architects - whoever is writing your correlation rules and searches - can write one search that will catch all of the instances of a given type of traffic or event without worrying about the specific source for that event.
Multiple data sources with multiple vendors for the same data domain
Do you have Windows, Linux and MacOS in your network? No problem. The same correlation search can tackle all authentication events.
Do you have multiple Databases? Or multiple browsers or types of web servers? If the data is sent to the Splunk platform and normalized into the Common Information Model, that data can be searched using the data models.
Accelerated searching capabilities
Data models are commonly used for acceleration or summarization. Using a data model makes your searching faster and more efficient. Summarization allows you to retrieve data from the data model more quickly than if you were searching the data from a raw index.
User roles
| Role | Responsibilities |
|---|---|
| Splunk Admin, Splunk Enterprise Security Admin | Data onboarding, app installs, index creation, permissions changes |
Preparation
1. Prerequisites
Install the Technical Add-on (TA) from Splunkbase for any data source you are onboarding. For example, the Splunk Add-on for Microsoft Windows and the Splunk Add-on for Unix and Linux. You can search for a TA for your other data sources on splunkbase.com. These provide pre-built configurations to quickly and efficiently ingest your data into Splunk software.
Additionally, you should install the following free apps for best results:
2. Recommended training
Splunk recommends the following Splunk EDU training courses for those who will be responsible for tasks related to getting data in and data normalization:
4. Considerations
Data onboarding is an iterative process that will likely be a continuous process. As you and other teams across the organization generate data, the need to ingest the data into Splunk software will be in demand. It is important to spend the time to ingest the data properly and ensure the integrity of the data before moving on. Establish a solid process and use Splunk On-Demand-Services or Assigned Expert resources if needed. It is well worthwhile to do it right the first time.
Implementation guide
1.0 Data source planning
Data sources for security events include a number of different technology domains. In order to provide the most relevant information to a security alert and for a potential investigation, you must have the details of what happened, and who did what. You will need to collect and correlate data from a wide range of data sources in order to properly investigate an event.
The typical data sources needed are network data such as network capture, firewall traffic, proxy devices, and intrusion detection systems.
It is important to have authentication events from different sources that tell you what is happening on devices across your organization. Asset and identity information is essential to the foundation of security events. This includes information about your users from an HR system, or events from a system like Active Directory and LDAP.
By collecting all of these data sources together, Splunk Enterprise Security can then run correlation searches against all of this data. Without the proper information about the user or system, it’s difficult to stitch together the information needed to investigate or troubleshoot an alert.
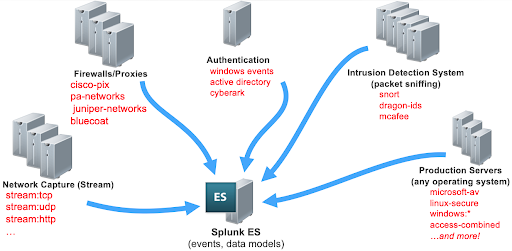
Firewall and proxy data can give you an idea of which assets and users have communicated with internal or external systems.
Some examples of detections you might use firewall or proxy data for are:
- Denied outbound traffic
- Protocol-port mismatches
- Excessive denies from a single external source
- 100+ distinct external IP address initiating a connection to the same target IP over distinct destination port in every 5 minutes or last 30 minutes
- A scan followed by a port opening
This is far from an exhaustive list. Understanding the logs will come with time, and it is worth researching each individual threat as you see it come in to the system. Intrusion detection, network capture, and packet sniffing tools can be very useful when attempting to connect the various parts of an attack.
Use the documentation on data source planning for Splunk Enterprise Security for more detailed information.
2.0 Using Splunk Security Essentials for data source planning
Splunk Security Essentials is a free app on Splunkbase. You can use Splunk Security Essentials to define and understand what sources of data you currently have, what sources you need in order to achieve your goals, and what security detections you can actually run against the data you have.
If you review the Splunk Security Essentials Data Inventory, you will be able to see a listing of your currently on-boarded data sources in your Splunk instance, and which of those actually map to existing security areas. To do this:
- Go to your Apps dropdown and select Splunk Security Essentials.
- Click on the Data dropdown.
- Select Data Inventory.
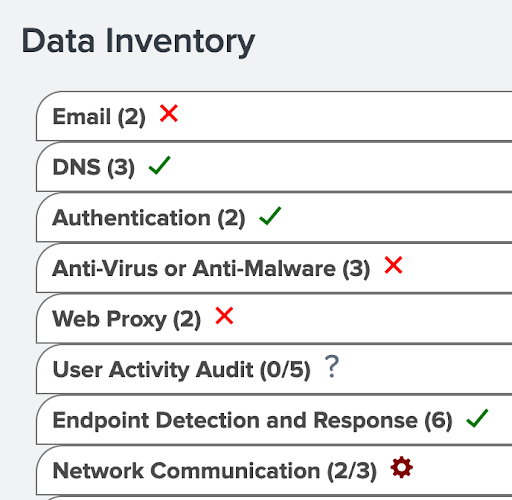
The Data Inventory can be useful for defining the types of sources you should be collecting, and whether you have those in your environment.
The following material can be helpful in using the SSE app to determine what sources you have and what you might be missing, further your data source maturity, and get the most out of your data:
3.0 Common Information Model (CIM)
The Splunk Common Information Model (CIM) is a “shared semantic model focused on extracting value from data.” It is used to normalize your data to match a common standard. For example, when you search for an IP address, different data sources may use different field names such as ipaddr, ip_addr, ip_address, or ip. The CIM normalizes different data sources to use the same field name for consistency across all sources. This normalization is especially important when you are ingesting data from multiple sources, which can cause problems if they are not standardized with a time synchronization mechanism.
To get started using the Splunk Common Information Model, follow the steps in Set up the Splunk Common Information Model Add-on.
4.0 Data models
Data models allow you to specify a class of data and retrieve the events associated with that data just by calling the class, rather than by having to understand the underlying syntax for each and every data source.
Data model definitions contain a hierarchy of data sets that then subdivide events into separate classes of events. A good example of this is the authentication data model. This is one of the most important data models in Splunk Enterprise Security, as it gathers events from all data sources and indexes that are tagged with the authentication tag. Using the authentication data model, you don’t have to specify whether you need Windows authentication or network authentication. The model contains all authentication events and you don’t need to know which source type or index it comes from.
Because there are so many different data sources that may contain authentication, having a way to normalize the data fields from different vendors is important to provide a unified view. Almost all of the existing reports, dashboards, and correlation searches included in Splunk Enterprise Security are designed to reference a normalized data model rather than any specific raw log. Using data models allows you to report on data from different vendors without having to redesign your searches and reports. Adding a new data source to a data model automatically includes it in the results. From then on, you should use these data models rather than individual sources to search or correlate your data.
In addition to taking the Splunk EDU class for Data Models listed above in the recommended training, follow the steps in Configure data models for Enterprise Security to get started with data models.
The Splunk Common Information Model (CIM) contains several data models out-of-the-box including Authentication, Data Access, Endpoint, Email, and Network Access.
Success measurement
Having good data that you can rely on is foundational to all other tasks in a security information and event management (SIEM) system. Following this guidance and getting your data CIM-compliant will benefit your environment for years to come.
When implementing this guidance, you should see improvements in the following:
- Data availability and coverage for detections and use cases
- Data reliability and integrity
- CIM compliance and data models
- Assets and identities data coverage