Lookup table creation for scalable anomaly detection with JA3/JA3s hashes
You can run a search that uses JA3 and JA3s hashes and probabilities to detect abnormal activity on critical servers, which are often targeted in supply chain attacks. JA3 is an open-source methodology that allows for creating an MD5 hash of specific values found in the SSL/TLS handshake process, and JA3s is a similar methodology for calculating the JA3 hash of a server session.
Required data
In this example, Zeek is used to generate JA3 and JA3s data but you can use any other tool which can generate that data.
Procedure
These searches are most effectively run in the following circumstances:
- with an allow list that limits the number of perceived false positives.
- against network connectivity that is not encrypted over SSL/TLS.
- with internal hosts or netblocks that have limited outbound connectivity as a client.
- in networks without SSL/TLS interceptions or inspection.
-
Run the following search to generate your lookup table. You can optimize it by specifying an index and adjusting the time range.
sourcetype="bro:ssl:json" ja3="*" ja3s="*" src_ip IN (192.168.70.0/24) | eval id=md5(src_ip+ja3+ja3s) | stats count BY id,ja3,ja3s,src_ip | eventstats sum(count) AS total_host_count BY src_ip,ja3 | eval hash_pair_likelihood=exact(count/total_host_count) | sort src_ip ja3 hash_pair_likelihood | streamstats sum(hash_pair_likelihood) AS cumulative_likelihood BY src_ip,ja3 | eval log_cumulative_like=log(cumulative_likelihood) | eval log_hash_pair_like=log(hash_pair_likelihood) | outputlookup hash_count_by_host_baselines.csv
Search explanation
The table provides an explanation of what each part of this search achieves. You can adjust this query based on the specifics of your environment.
Splunk Search Explanation sourcetype="bro:ssl:json" ja3="*" ja3s="*" src_ip IN (192.168.70.0/24)Search for JA3 and JA3s hashes within the critical server defined.
This part of the search uses critical server netblock, 192.168.70.0/24. It's important that you adjust this part of the search to include your own critical servers.
| eval id=md5(src_ip+ja3+ja3s)Create a new field, id, with a message-digest (MD5) 128-bit hash value for ',
JA3, andJA3s.| stats count BY id,ja3,ja3s,src_ipCount by
ID,JA3,JA3s, andsrc_IP.To ensure the probabilities stay up-to-date, you must run an additional query to ensure the latest information is in the lookup table. You can do this by inserting the additional SPL shown here after this line of the original search. While the initial outputlookup query should have a time window of the previous 7 days, this update query should run every 24 hours during the last 24 hours' worth of data. You can append the content from the previous query and restrict the time window to start when the last one is completed.
| append
[| inputlookup hash_count_by_host_baselines.csv]
| stats sum(count) as count by id,ja3,ja3s,src_ip| eventstats sum(count) AS total_host_count BY src_ip,ja3Count the number of events using
total_host_count, and count bysrc_ipandJA3.| eval hash_pair_likelihood=exact(count/total_host_count)Evaluate the likelihood of an exact match of the events total_host_count.| sort src_ip ja3 hash_pair_likelihoodSort src_ip,JA3, andJA3s.| streamstats sum(hash_pair_likelihood) AS cumulative_likelihood BY src_ip,ja3Calculate a cumulative probability for the events grouped by src_ipandJA3.| eval log_cumulative_like=log(cumulative_likelihood)
| eval log_hash_pair_like=log(hash_pair_likelihood)Create a field called log_cumulative_likethat calculates the logarithm of thecumulative_likelihoodvalue with base 10. Then do the same forlog_hash_pair_like.| outputlookup hash_count_by_host_baselines.csvDisplay the results in a lookup table CSV. -
Run the following search with the lookup command to identify anomalous activity. You can optimize it by specifying an index and adjusting the time range.
sourcetype="bro:ssl:json" ja3="*" ja3s="*" src_ip IN (192.168.70.0/24) | eval id=md5(src_ip+ja3+ja3s) | lookup hash_count_by_host_baselines.csv id AS id OUTPUT count, total_host_count,log_cumulative_like, log_hash_pair_like | table _time, src_ip, ja3s, server_name, subject, issuer, dest_ip, ja3, log_cumulative_like, log_hash_pair_like, count, total_host_count | sort log_hash_pair_like
Search explanation
The table provides an explanation of what each part of this search achieves. You can adjust this query based on the specifics of your environment.
Splunk Search Explanation sourcetype="bro:ssl:json" ja3="*" ja3s="*" src_ip IN (192.168.70.0/24)Search for JA3 and JA3s hashes within the critical server defined.
This part of the search uses critical server netblock, 192.168.70.0/24. It's important that you adjust this part of the search to include your own critical servers.
| eval id=md5(src_ip+ja3+ja3s)Create a new field, id, with a message-digest (MD5) 128-bit hash value for
src_IP,JA3, andJA3s.| lookup hash_count_by_host_baselines.csv id AS id OUTPUT count, total_host_count,log_cumulative_like, log_hash_pair_likeLook up the id hash within the table previously generated and output the fields shown. | table _time, src_ip, ja3s, server_name, subject, issuer, dest_ip, ja3, log_cumulative_like, log_
hash_pair_like, count, total_host_countDisplay the results in a table with columns in the order shown. | sort log_hash_pair_likeSort the results with the smallest log_hash_pair_likevalue first.
Next steps
This part of the search means you can look up the ID generated previously in your lookup table to hone in on potentially anomalous results. In the example below, anomalous results are returned in the top ten results.
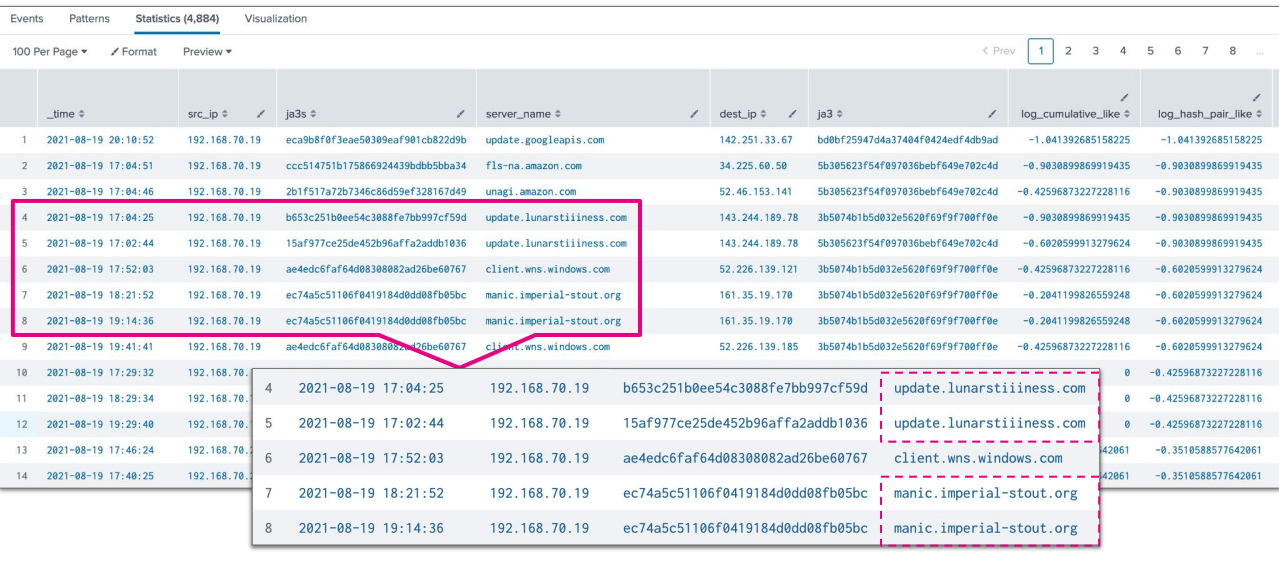
Results from this search are of similar effectiveness and an equivalent amount of time for the queries to complete when compared to the anomaly probability search. However, in general, day-to-day usage, it is approximately 100x faster when compared with the secondary lookup query.
An allow list could also be a necessity when tested with more extensive networks so that anomalous activity is consistently identified within the top 30 events.
Finally, you might be interested in other processes associated with the Detecting software supply chain attacks use case.