Defining and detecting personally identifiable information in log data
You work for an organization that handles customer personally identifiable information (PII). You have a duty of care to your users and customers to make sure that PII isn't exposed to the outside world, while also meeting security, compliance, and regulatory requirements to keep it internal and intact. The challenge you have is that PII appears in unexpected places in your log files. Because your data is also ingested into your Splunk deployment, you are concerned it could enter indexes where teams without the appropriate authority can see it.
Part of the problem with identifying PII is that defining it can be tricky. Direct PII, such as email addresses or credit card numbers, can be fairly straightforward to identify by looking at the way it's formatted. But PII can also be indirect and less easy to identify from raw data, such as medical information, employment history, or descriptive information about an individual. You need to be able to identify the types of PII that are meaningful to your organization, and also provide feedback to your developers and operational teams on where it's turning up so they can better secure it.
Data required
How to use Splunk software for this use case
The app PII Tools allows you to use a number of different methods for analysis to define and detect PII in your log data. Some methods are quicker and more lightweight than others, and you can choose which method or combination of methods works well for your organization.
Log vocabulary monitoring
Log vocabulary monitoring is lightweight and fast, and you can apply this method across a large amount of data, although it is the least precise of the methods described in this article. The reason for this speed is that the raw data itself is not searched. Instead, search terms are pulled directly from index lexicons and classified using a dictionary lookup into terms like first names, surnames, medical terms, elements of street addresses, as well as other specific terms such as "account number". Seeing these types of terms in indexes where you wouldn't expect to see them would then prompt further investigation.
Log vocabulary monitoring also looks at changes in log vocabulary over time. Logs generally have a limited and fairly unchanging vocabulary. If your logs start increasing the vocabulary they are using, for example by increasing the number of adjectives used or by changing the tense they use, that can often be a sign that they contain data that's different from the norm, and they might contain PII.
To search for PII using this method within the PII Tools app, open the app and click Index Vocabulary. On the top-left of the dashboard, as shown in the example below, you can see a legend that categorizes search terms that have been pulled directly from your index lexicons. There are different colors used for adjectives, adverbs, first names, surnames, prepositions, medical terms, and more. On the right-hand side, the charts represent different indexes that show how the index vocabulary has changed over time. In this example you can see that in the main index, in June, there was a sudden influx of first names, addresses and surnames, indicating that PII might have entered the data around that time.
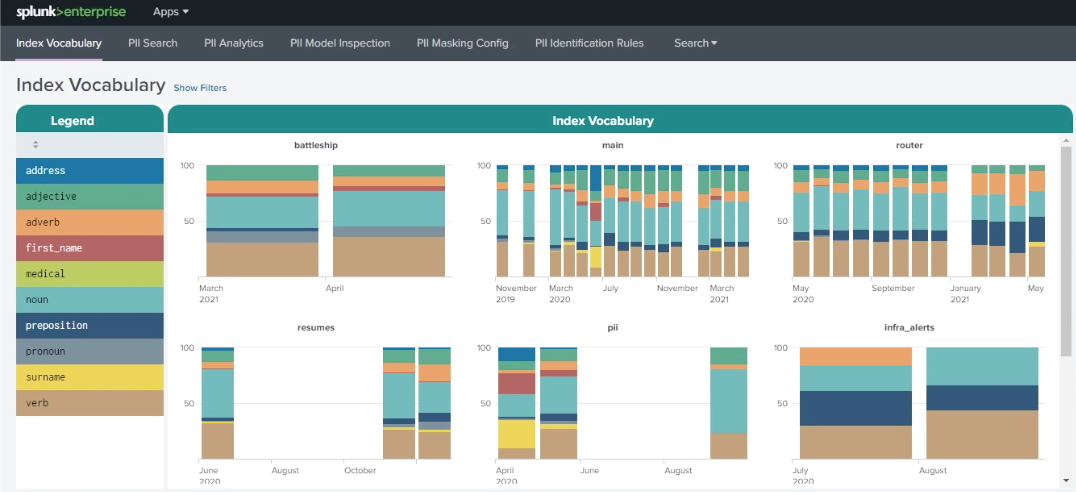
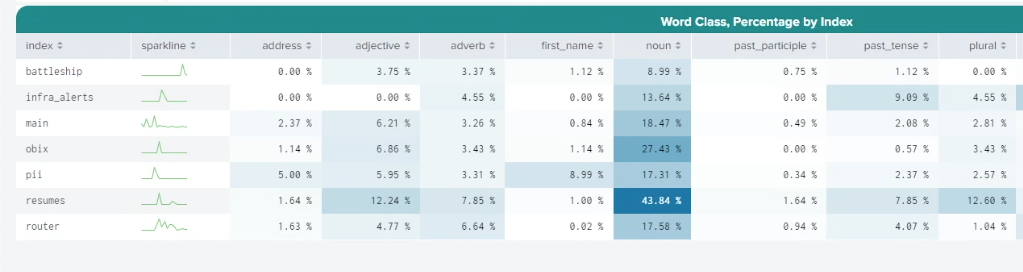
Further down the screen, the Word Class, Percentage by Index table shows baselines for the different search term categorizations. In the example below, the resumes index contains a much higher proportion of nouns than the infra_alerts index. Because human data tends to have a much wider and more creative vocabulary than machine data, this could be expected. You can use this information to help you baseline what's normal for your different indexes.
Rule-based analytics and risk scoring
Rule-based analytics and risk scoring is more resource intensive than log vocabulary monitoring but provides a more specific and targeted approach to detecting PII.
First, it uses rules to look for patterns like email addresses or phone numbers, using tools like the Luhn algorithm which scores numeric terms to see if they're likely to be a credit card number. You can set up rules based on a single criterion, or you can create more nuanced detections by combining several rules. For example, you might decide that it's fine if a first name turns up in a log, but if you see a first name and a surname, and an email address or phone number, that's when you want to be alerted.
To search for PII using this method within the PII Tools app, open the app and click PII Search. Select a time range for your search, and, optionally, specify indexes and source types. Under Select Features to Include, select whether you want to search for Dictionary Terms, Formatted Numbers, or Grammatical Elements.
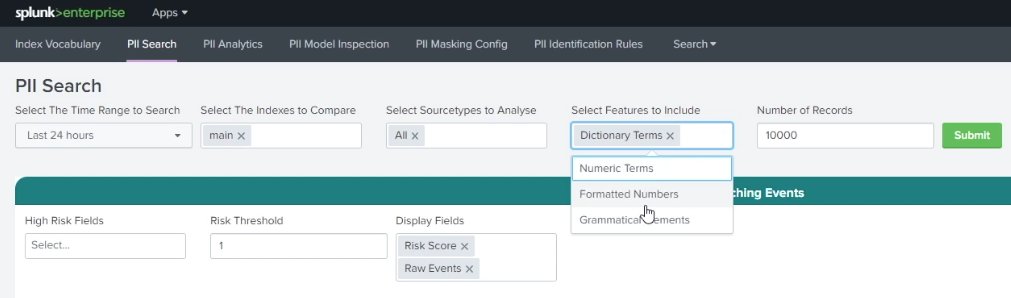
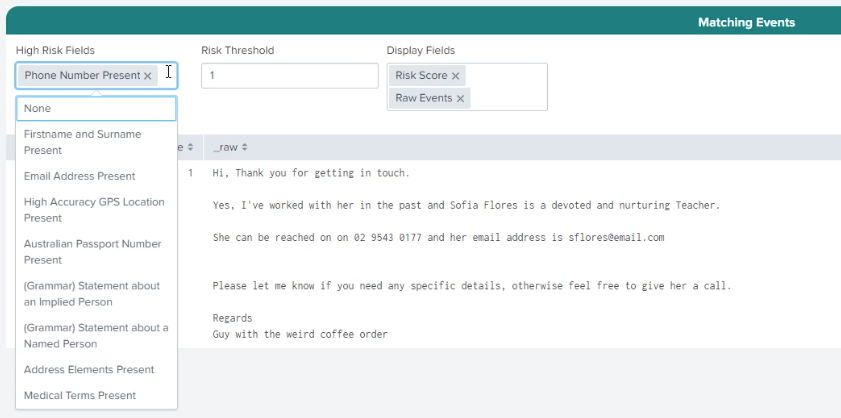
Different types of organizations have different types of PII that they want to be alerted to, depending on geography, legislation, or company policy. Under High Risk Fields you can choose individual PII types or combinations of them to base your rules on. The PII Search shows you the raw data associated with events that match that rule. In the example below, you can see that Phone Number Present has been selected, and data containing a phone number can be seen as a matching event. You can also set a Risk Threshold to fine-tune when you want to be alerted.
Machine learning-based detection of PII
Machine learning-based detection of PII is resource intensive but powerful. Applying machine learning to the detection of PII means that a trained model can identify PII from similar types of PII it has been trained to identify, even if the new data it's encountering is not exactly similar. After the model is trained, it can be used directly in an alert to let you know if something unusual has occurred. You can also inspect a large number of machine learning models to understand what they've detected as key indicators of personally identifiable information, which can yield insights that you might not initially have been looking for.
Machine learning models need a large amount of data to train them, which means you need data that has been already identified as containing PII. That data needs to be processed into a format that machine learning algorithms can deal with via the process of feature extraction via regex to pull out features like numeric strings, certain words, strings of characters or number formats. The data is enriched with a dictionary lookup, lemmatizing it, and then back substituting when necessary, and selecting which features are going to be most helpful for that machine learning algorithm to detect PII. Finally, this data set is split into two groups, a training data set of about 70% of the data which you can use to train the algorithm, and a test set which you can use later to test whether the algorithm is successful or not.
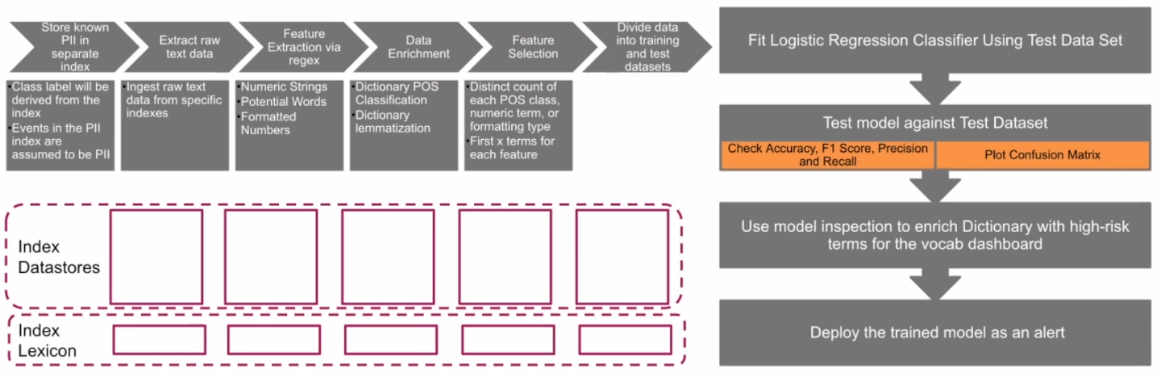
The PII Tools app puts this pipeline into a dashboard for you to work from to train a model for use on your own data.
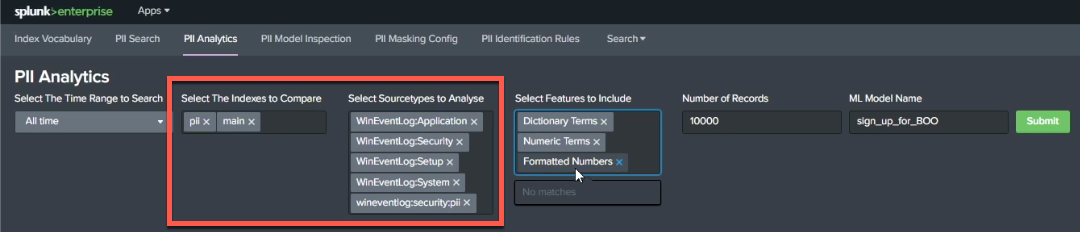
Start by opening the app and clicking PII Analytics. First, under Select The Indexes to Compare, specify indexes to compare. It's a good practice to select an index that you know contains PII, so your model has something to learn from, and also to select an index that's mostly clean. Examining a comparison of these indexes will guide you in assessing how successful your model is. You can also select source types to analyze. Similar to indexes, it's a good practice to add in infected and uninfected source types because logs all have their own unique vocabularies. Your model needs to understand what a clean application log is, how that is differentiated from an infected one. Giving it examples from a range of sources helps it learn this.
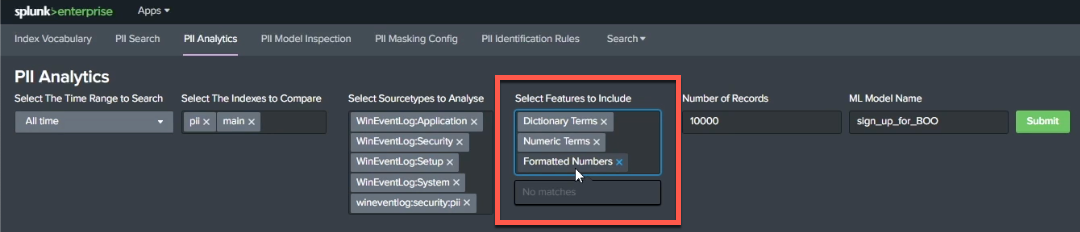
Next, convert your data into a format that a machine learning model can use. You can do this under Select Features to Include, which allows you to specify whether you want the model to be trained on dictionary terms, numeric terms, or by looking at how numbers are formatted (for example, helping your model identify that four groups of four numbers separated by hyphens is probably a credit card number.)
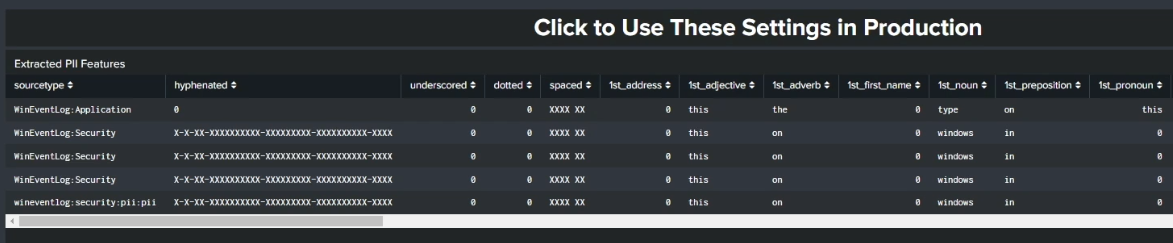
After you've selected the features you want your model to use, click Submit to start training the model. Further down the screen you'll see that a table has appeared that formats your inputs into the structured data that your model is learning from. The model has also already categorized each of the events it sees while training, identifying the different features you selected within the data set it is learning from.
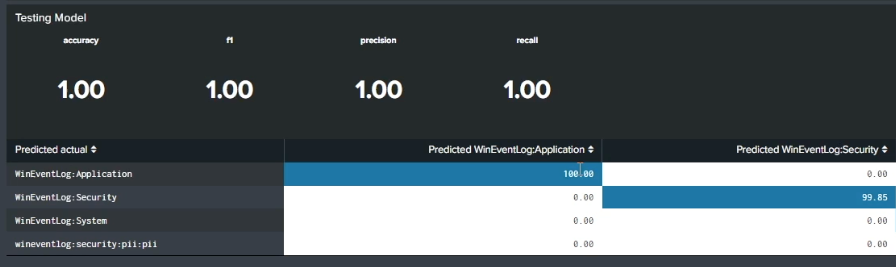
At the bottom of the screen is an assessment of the success of your new model. This information is obtained through testing the data that was held back from the original training data set. In the example below, there are very high accuracy, f1, precision, and recall scores. You can also see whether each source type was categorized successfully. In this example, 100% of the application logs identified in the training data were identified as application logs in the test data, indicating that the model has a good grasp of what the PII categories look like. You can compare source types across different indexes (whether infected with PII or not) to check that the data has been successfully categorized.
If you're seeing low scores in this area, adjust the PII Analytics indexes and source types until you get closer to a higher score.
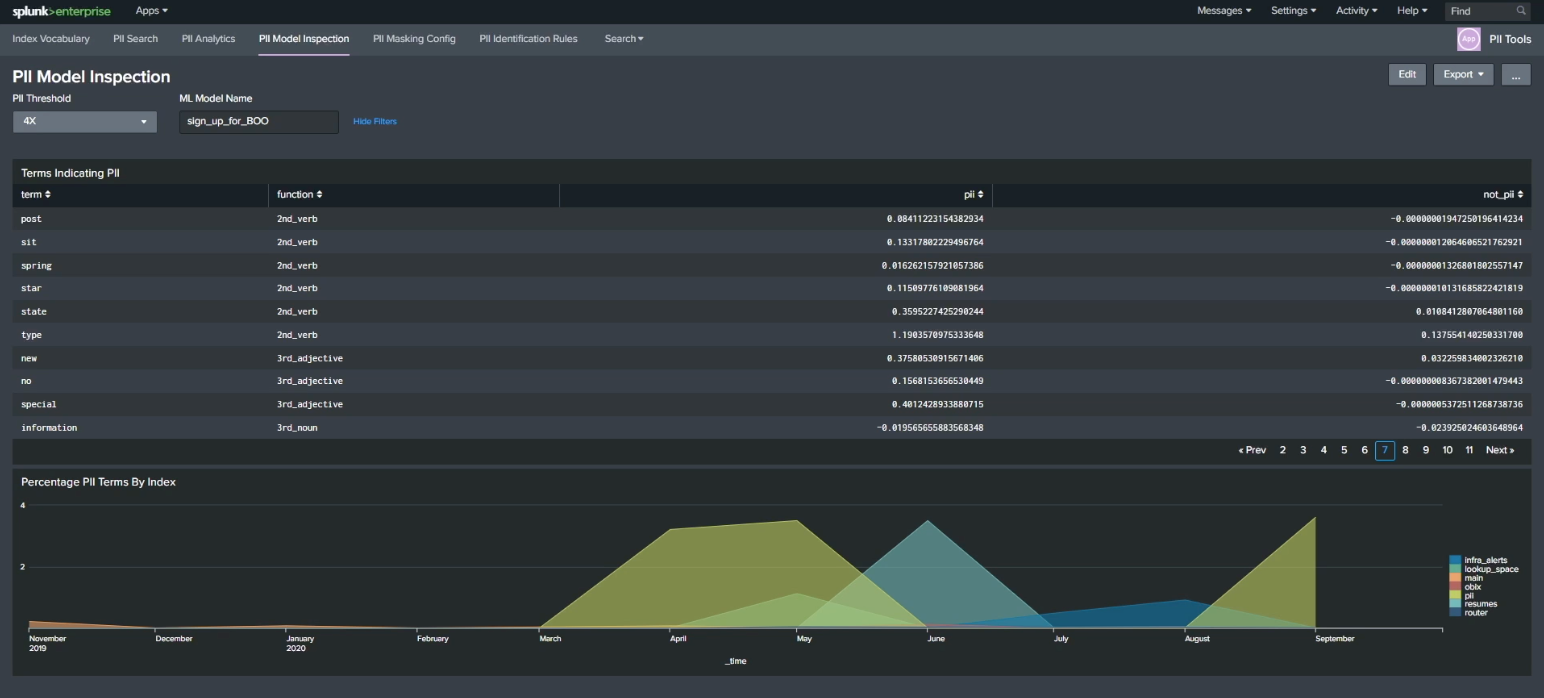
Now that you've trained your model, click the PII Model Inspection dashboard to inspect what it actually found. The model you've trained to identify linkages, indicators, terms, and values that indicate a probability of PII can now be used to examine other data in your indexes. The chart at the bottom of this screen shows potential PII terms per index that can help you categorize and classify PII as it flows into your indexes in real time.
Next steps
The content in this article comes from a .Conf talk, one of the thousands of Splunk resources available to help users succeed. In addition, these resources might help you understand and implement this guidance:
- Splunk Lantern Article: Detecting Personally Identifiable Information (PII) in log data for GDPR compliance
- Splunk Lantern Article: Running common General Data Protection Regulation compliance searches