Properly securing Splunk indexes
Determining how to secure your indexes and data models is part of your organization’s operational security. Applying permissions to your indexes is a crucial exercise, but documenting the roles can be daunting. Using role-based access control (RBAC) to restrict indexes has several advantages and can be applied to indexes, data models, and events. Leveraging metadata can make this process more efficient.
There are many reasons that you might need an index with restrictive permissions. You might have personally identifiable information, indexes that have the potential to contain this information, or other compliance needs.
This article assumes that you are hosting a single tenant Splunk organization and are not responsible for multiple tenants within the same Splunk instance.
Because of its complexity, security methodologies such as attribute-based access control (ABAC) are out of the scope of this article. Review this conf talk for more details about implementing ABAC.
How to use Splunk software for this use case
Security architecture
Splunk RBAC influences security on an object such as an index; however, subsets such as source types cannot have RBAC applied. So, as a result, the entire index needs to be secured. This might present a problem if source types present within an index need to be accessed by separate security groups. Therefore, careful consideration must be made if you are subject to certain compliance frameworks, such as the General Data Protection Regulation (GDPR). To prevent data exposure from non-authorized groups, it's critical to secure the index.
Other caveats that might affect a secure data infrastructure include:
- Search macros. The scope of the search macros should be evaluated to prevent data leakage.
- Data models. These are difficult to secure because they are designed to be shared across multiple indexes.
- Data Model Acceleration (DMA). Object level permissions are maintained, however, careful emphasis on performance architecture must be observed.
Default access and role inheritance
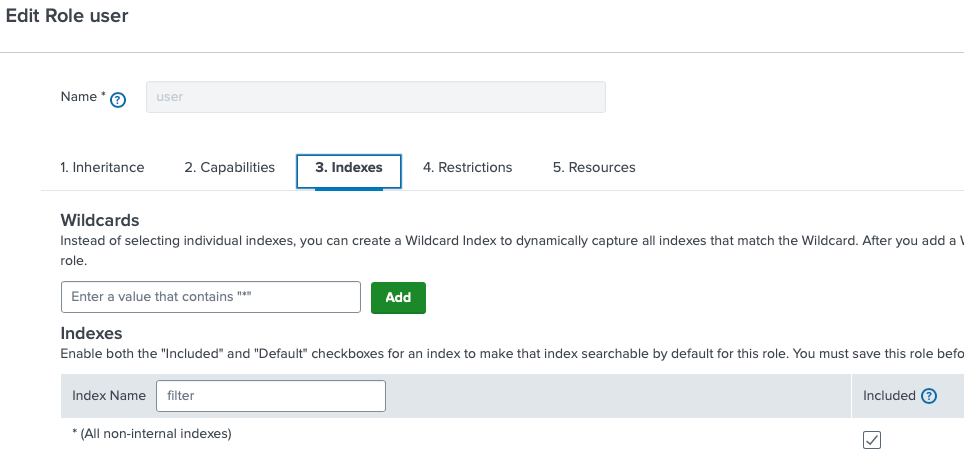
When working with existing roles, it’s important to consider that default values affect access to indexes. For example, the user role has access to all non-internal indexes by default. If you're creating a new index that is meant for another role, then these values need to be changed. If you uncheck the All non-internal indexes under the Indexes tab for the user role, all indexes will clear and allow you to reconfigure the role for the indexes that are appropriate for that role. The image below illustrates this.
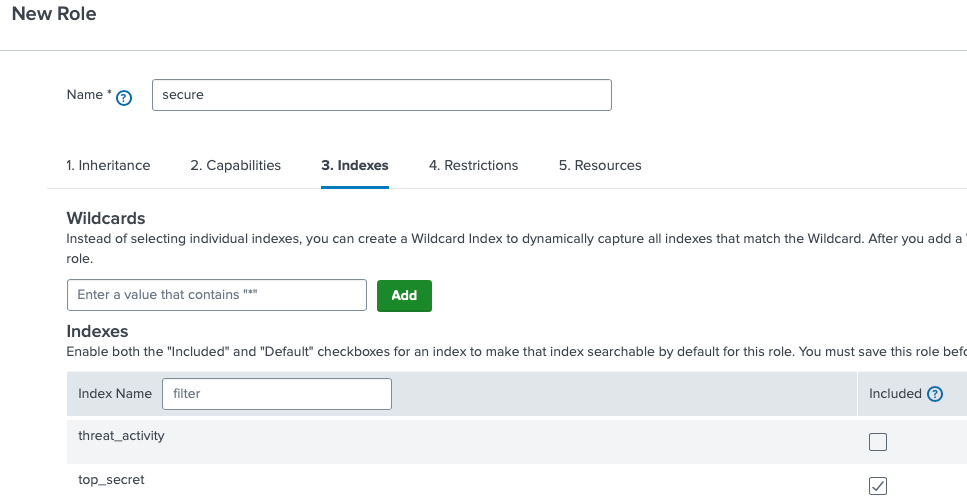
Creating a new role allows the Splunk administrator to manually assign only the indexes that are needed so any users assigned to that role can view the contents of the index. The image below shows an example.
If the new role you're creating requires capabilities that overlap with another role, the clone action might save you time. Be sure to review its inherited capabilities before duplicating the role.
Search filters versus index restrictions
Security practitioners might consider using search filters in an attempt to obfuscate data, but there are some caveats to this approach. For example, search filters can be bypassed by conflicting inheritance settings. If a user has a role that grants access to one index and also is part of another that doesn’t, then that user could access it since the most permissive are applied.
- Search filters:
- Are not security controls and can be bypassed.
- Can be circumvented by knowledge object (KO) permissions, including shared KOs.
- Cannot be applied to accelerated data models.
- Index restrictions: Applying roles to indexes is often the best choice for Splunk administrators. For example, entering a wildcard to bring up all indexes like
index=*will show only the indexes that users have access to.
Although this article's main focus is index security, other factors, such as retention policies, might need to be considered. Certain sets of data might require different retention policies. Data retention is managed on an index level. If special data handling is required within the index, for example a consultant with different retention needs from your main team needs access to it, then that data should be broken out into a separate index.
Performance considerations
When reviewing changes to your operational security, performance effects on the Splunk system must be considered.
- Data retention policies: Longer retention policies will affect DMA build times and disk size.
- Data model acceleration: Although there are security advantages to using DMA, additional storage space is required if several data models are being accelerated.
- Search performance: Mixing dissimilar data into large indexes might reduce the performance of the index and will result in longer running searches.
Next steps
These resources might help you understand and implement this guidance:
- Splunk Help: Use access control to secure Splunk data
- Splunk Help: About users and roles
- Splunk Lantern Article: Unauthorized access to Splunk indexes
- Splunk Lantern Article: Managing data based on role