Combining multiple data sources in SPL
Depending on your use case or what you are looking to achieve with your Search Processing Language (SPL), you may need to query multiple data sources and merge the results.
The most intuitive command to use when these situations arise is the join command, but it tends to consume a lot of resources - especially when joining large datasets. This article describes the following additional commands and functions that can be applied when combining data from multiple sources, including their benefits and limitations.
OR boolean operator
The most common use of the OR operator is to find multiple values in event data, for example, foo OR bar. This tells Splunk platform to find any event that contains either word. However, the OR operator is also commonly used to combine data from separate sources, for example (sourcetype=foo OR sourcetype=bar OR sourcetype=xyz).
Additional filtering can also be added to each data source, for example, (index=ABC loc=Ohio) OR (index=XYZ loc=California). When used in this manner, Splunk platform runs a single search, looking for any events that match any of the specified criteria in the searches. The required events are identified earlier in the search before calculations and manipulations are applied.
Learn more about using the OR operator in Splunk Docs for Splunk Enterprise or Splunk Cloud Platform.
Syntax for the OR operator
(<search1>) OR (<search2>) OR (<search3>)
Pros
- Merges fields and event data from multiple data sources
- Saves time since it does only a single search for events that match specified criteria and returns only the applicable events before any other manipulations
Cons
- Only used with base searches
- Does not allow calculations or manipulations per source, so any further calculations or manipulations need to be performed on all returned events
In the example below, the OR operator is used to combine fields from two different indexes and grouped by customer_id, which is common to both data sources.
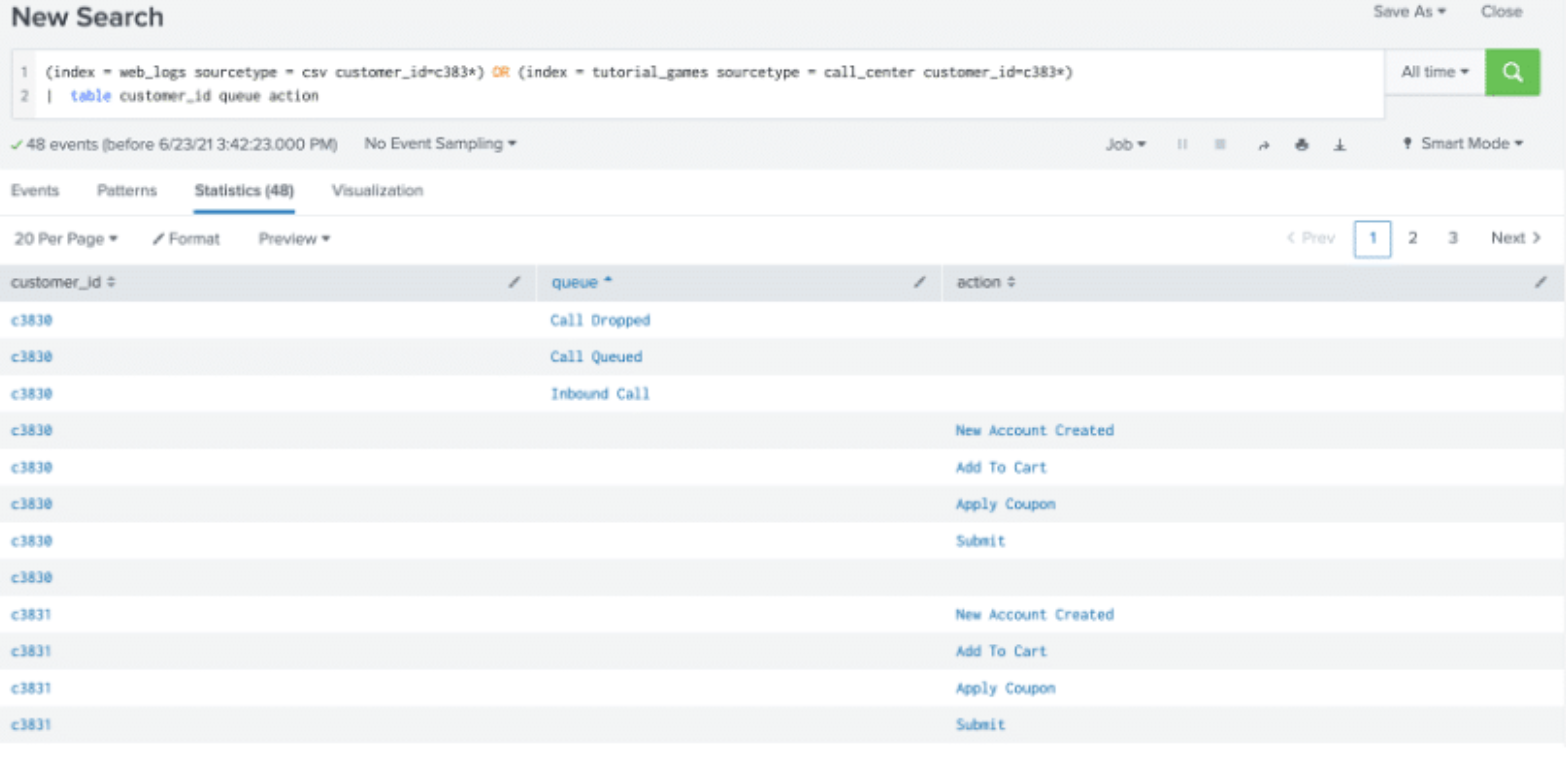
Append command
Append is a streaming command used to add the results of a secondary search to the results of the primary search. The results from the append command are usually appended to the bottom of the results from the primary search. After the append, you can use the table command to display the results as needed.
The secondary search must begin with a generating command. Append searches are not processed like subsearches where the subsearch is processed first. Instead, they are run at the point they are encountered in the SPL.
Learn more about using the append command in Splunk Docs for Splunk Enterprise or Splunk Cloud Platform.
Syntax for the append command
<primary search> ... | append [<secondary search>]
Pros
- Displays fields from multiple data sources
Cons
- Subject to a maximum result rows limit of 50,000 by default
- The secondary search must begin with a generating command
- It can only run over historical data, not real-time data
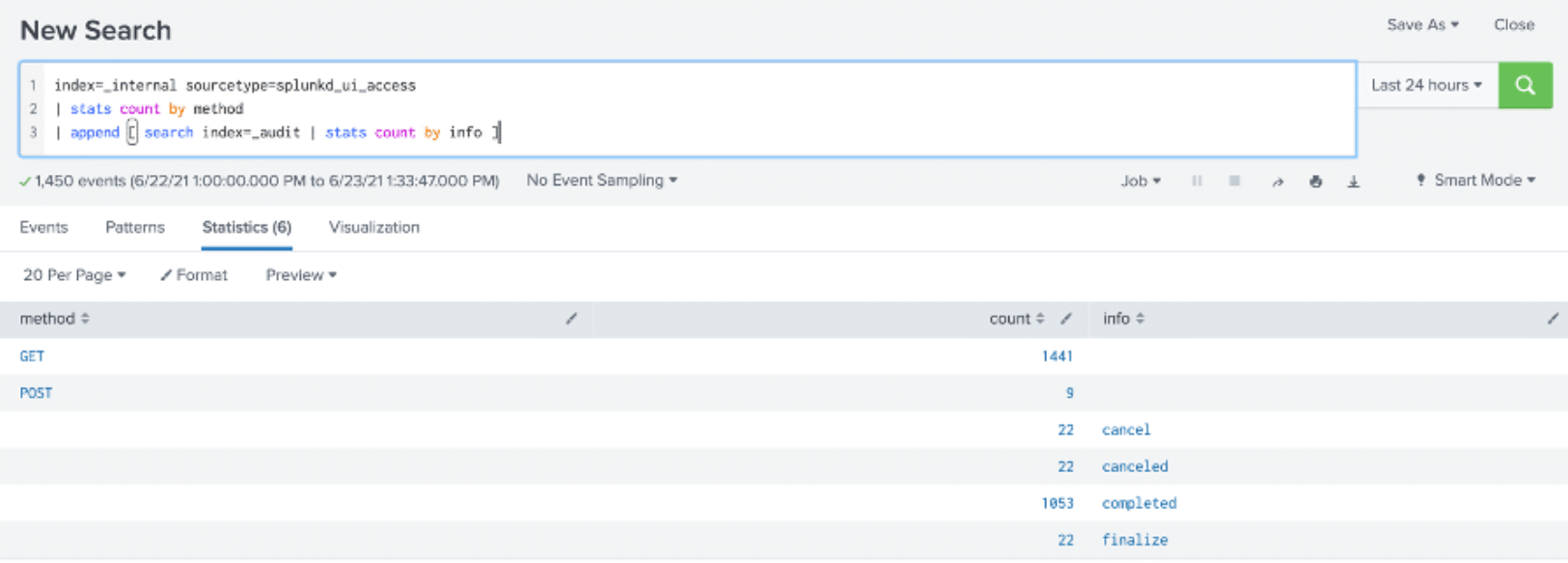
In the example below, the count of web activities on the Splunk user interface is displayed from _internal index along with count per response from the _audit index.
The last four rows are the results of the appended search. Both result sets share the count field. You can see that the append command tacks on the results of the subsearch to the end of the previous search, even though the results share the same field values.
Multisearch command
Multisearch is a generating command that runs multiple streaming searches at the same time. It requires at least two searches and should only contain purely streaming operations such as eval, fields, or rex within each search.
One major benefit of the multisearch command is that it runs multiple searches simultaneously rather than sequentially as with the append command. This could save you some runtime especially when running more complex searches that include multiple calculations and/or inline extractions per data source. Results from the multisearch command are interleaved, not added to the end of the results as with the append command.
Learn more about using the multisearch command in Splunk Docs for Splunk Enterprise or Splunk Cloud Platform.
Syntax for the multisearch command
| multisearch [<search1>] [<search2>] [<search3>] ...
Since multisearch is a generating command, it must be the first command in your SPL. It is important to note that the searches specified in square brackets above are not actual subsearches. They are full searches that produce separate sets of data that will be merged to get the expected results. A subsearch is a search within a primary or outer search. When a search contains a subsearch, the Splunk platform processes the subsearch first as a distinct search job and then runs the primary search.
Pros
- Merges data from multiple data sources
- Runs searches simultaneously, thereby saving runtime with complex searches
- There is no limit to the number of result rows it can produce
- Results from the
multisearchcommand are interleaved, allowing for a more organized view
Cons
- Requires that the searches are entirely distributable or streamable
- Can be resource-intensive due to multiple searches running concurrently. This needs to be taken into consideration since it can cause search heads to crash
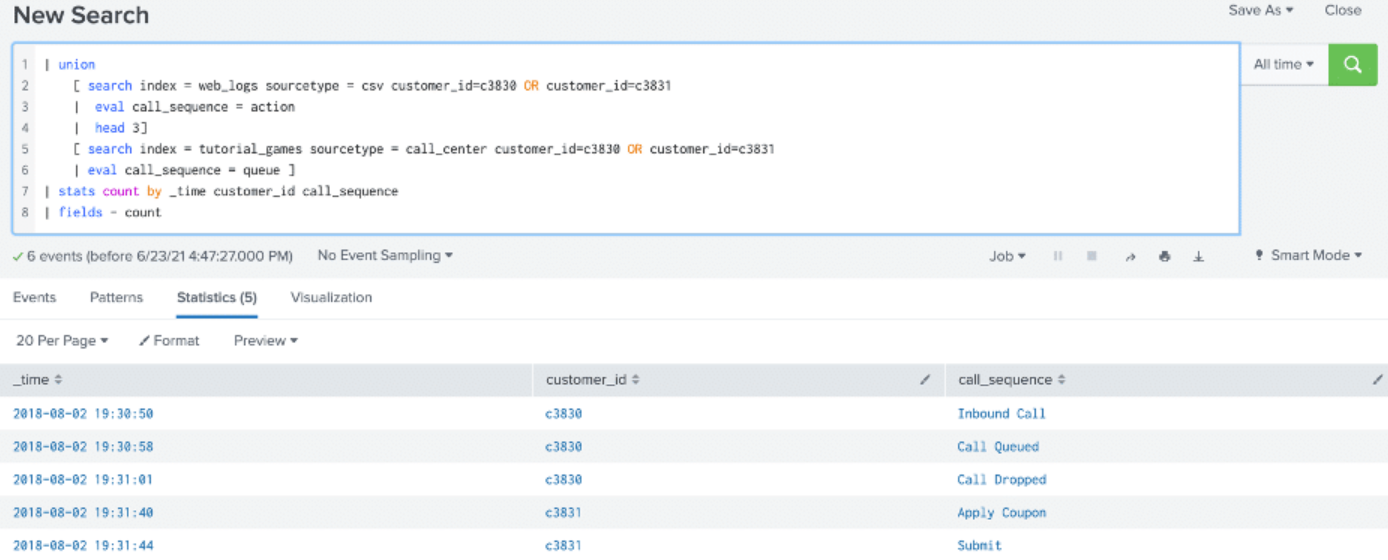
In the example shown below, the multisearch command is used to combine the action field from the web_logs index and queue field from the tutorial_games index using the eval command to view the sequence of events and identify any roadblocks in customer purchases. The results are interleaved using the _time field.
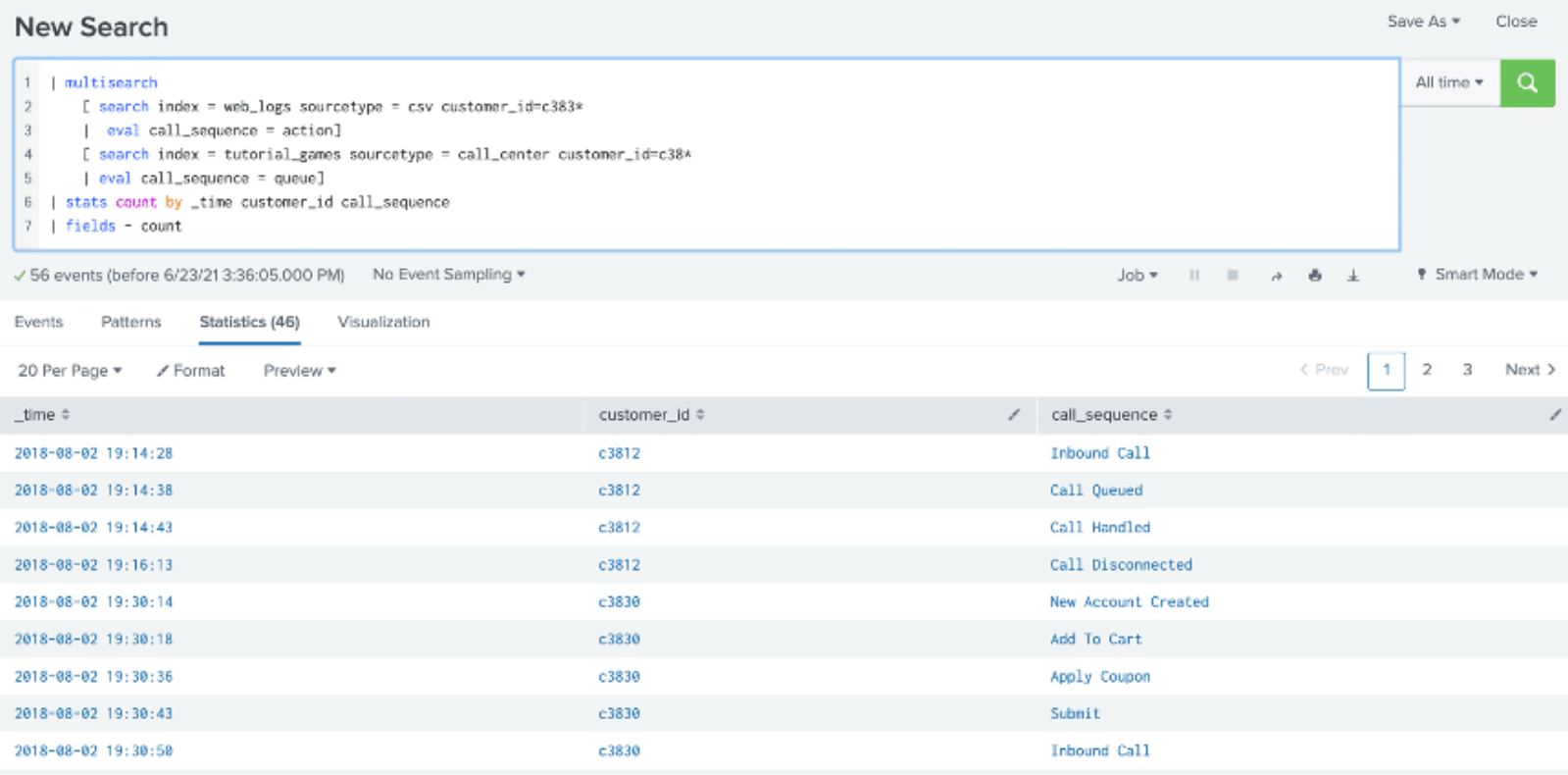
Union command
Union is a generating command that is used to combine results from two or more datasets into one large dataset. The behavior of the union command depends on whether the dataset is a streaming or non-streaming dataset. Centralized streaming or non-streaming datasets are processed the same as append command while distributable streaming datasets are processed the same as multisearch command.
Learn more about using the union command in Splunk Docs for Splunk Enterprise or Splunk Cloud Platform.
Syntax for union command
| union [<search2>] [<search2>] … OR … | union [<search>]
However, with streaming datasets, instead of this syntax:
<streaming_dataset1> | union <streaming_dataset2>
Your search is more efficient with this syntax:
... | union <streaming_dataset1>, <streaming_dataset2>
Pros
- Merges data from multiple data sources
- Can process both streaming and non-streaming commands, though behavior will depend on the command type
- As an added benefit of the max out argument, which specifies the maximum number of results to return from the subsearch. The default is 50,000 results. This value is the
maxresultrowssetting in the [searchresults] stanza in the limits.conf file.
The example below is similar to the multisearch example provided above and the results are the same. Both searches are distributable streaming, so they are “unioned” by using the same processing as the multisearch command.
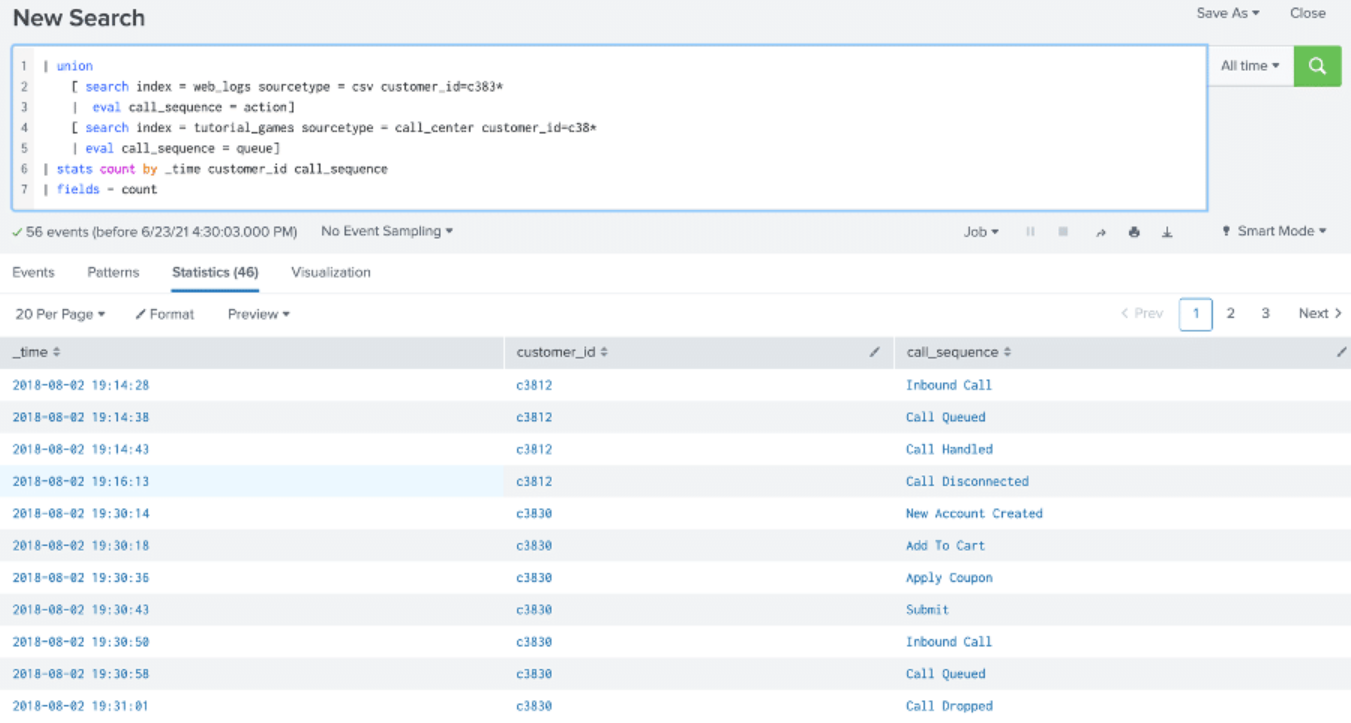
In the example below, because the head command is a centralized streaming command rather than a distributable streaming command, any subsearches that follow the head command are processed using the append command. In other words, when a command forces the processing to the search head, all subsequent commands must also be processed on the search head.
Comparing OR, Append, Multisearch, and Union
The table below shows a comparison of the four methods:
OR |
Append |
Multisearch |
Union |
|---|---|---|---|
| Boolean Operator | Streaming command | Generating command | Generating command |
| Used in between searches | Used in between searches | Must be the first command in your SPL | Can be either the first command or used in between searches. Choose the most efficient method based on the command types needed |
| Results are interleaved | Results are added to the bottom of the table | Results are interleaved | Results are interleaved based on the time field |
| No limit to the number of rows that can be produced | Subject to a maximum of 50,000 result rows by default | No limit to the number of rows that can be produced | Default of 50,000 result rows with non-streaming searches. Can be changed using maxout argument. |
| Requires at least two base searches | Requires a primary search and a secondary one | Requires at least two searches | Requires at least two searches that will be “unioned” |
| Does not allow use of operators within the base searches | Allows both streaming and non-streaming operators | Allows only streaming operators | Allows both streaming and non-streaming operators |
| Does only a single search for events that match specified criteria | Appends results of the subsearch to the results of the primary search | Runs searches simultaneously | Behaves like multisearch with streaming searches and like append with non-streaming |
Next steps
Want to learn more about combining data sources in Splunk? Contact us today! TekStream accelerates clients’ digital transformation by navigating complex technology environments with a combination of technical expertise and staffing solutions. We guide clients’ decisions, quickly implement the right technologies with the right people, and keep them running for sustainable growth. Our battle-tested processes and methodology help companies with legacy systems get to the cloud faster, so they can be agile, reduce costs, and improve operational efficiencies. And with hundreds of deployments under our belt, we can guarantee on-time and on-budget project delivery. That’s why 97% of clients are repeat customers.
The user- and community-generated information, content, data, text, graphics, images, videos, documents and other materials made available on Splunk Lantern is Community Content as provided in the terms and conditions of the Splunk Website Terms of Use, and it should not be implied that Splunk warrants, recommends, endorses or approves of any of the Community Content, nor is Splunk responsible for the availability or accuracy of such. Splunk specifically disclaims any liability and any actions resulting from your use of any information provided on Splunk Lantern.