Avoiding common pitfalls for getting data in
Getting data into the Splunk platform is straightforward most of the time, but there are common pitfalls that can be avoided if you know about them. This article discusses three common ones.
Configure the HTTP Event Collector (HEC) input timestamp
The Splunk platform processes data coming in via HEC a little differently than it does a regular file input. This is related to how data is processed by the HEC data processing pipelines and the HEC endpoint used to send data to the Splunk platform.
If you use the raw HEC endpoint, it’ll be easy enough to parse the timestamp fields as you would any other source type (that is, by using the TIME_PREFIX and TIME_FORMAT settings).
When using the event HEC endpoint, pay attention to the placement of the time field for a given event. In this case, if your time field lives in the events sent to the Splunk platform and not in the HEC payload, the Splunk platform might default to using the time of ingestion instead of the time of the event itself. Consider the following HEC payload:
{
"event": {
"message": "Something happened",
"severity": "INFO”,
"time": 1437522387
}
}
The above event will be indexed using the time of ingestion instead of the time of the event. You’ll need to set the time field at the HEC payload level, or use the raw endpoint to ensure ease of timestamp parsing.
Alternatively, you can use INGEST_EVAL to set the _time field. The following is an example of how you might accomplish that for the example event above:
INGEST_EVAL=_time=strptime(replace(_raw,".+time\":\s\"(\d+),"\1"),"%s")
Additional information on the INGEST_EVAL command can be found here.
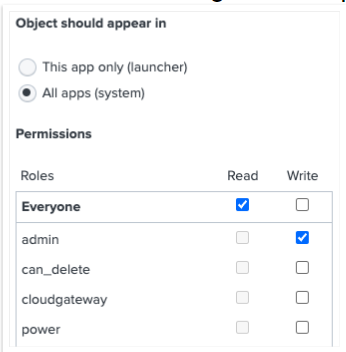
Share configurations system-wide
When creating custom configurations for your source types, make sure you share them at the appropriate level; otherwise things might not work correctly.
The following screenshot shows the permissions settings in the UI, but you can also set them using the Splunk metadata config files.
Index-time versus search-time field extractions
You can configure the Splunk platform to extract fields at search time or at index time. However, if you configure both, the Splunk platform will extract fields twice, leading to double the values in your search results, as shown here.

To avoid this, make sure you configure field extractions only at search time (which is generally preferable) or only at index time. This will apply on a per-source type basis.
For a given source type, in props.conf, use either:
INDEXED_EXTRACTIONS = JSON KV_MODE = none
or
INDEXED_EXTRACTIONS = KV_MODE = json
Next steps
These additional Splunk resources might help you get data into your Splunk deployment more easily:
- Flowchart: Splunk HTTP Event Collector (HEC) pipelines
- Splunk Community: Best practices for defining source types
- Splunk Lantern: Configuring new source types
- Splunk Lantern: Getting to know your data
- Splunk Lantern: Improving data onboarding with props.conf configurations