Establishing authentication requirements for node scaling automation (OnPrem)
Before we get into the details of building dynamic scaling for Splunk Edge Processor, we have to understand and prepare for on-demand authentication. You should familiarize yourself with the node install procedure before beginning.
In the following article, we’ll examine the Splunk Edge Processor node install script in depth, but for the purposes of this section it’s important to understand that the node install script requires that a valid token be provided. The line in question looks like this:
# Create a token file containing the authentication token that allows the Edge Processor instance to connect to the control plane echo "eyJhbGciOiJSUzI1NiIsImtpZCI6IlFnZlNhQ1NMUj…" > splunk-edge/var/token
When manually provisioning nodes, a valid and unexpired token is included in the script provided by the user interface. If you are provisioning nodes manually, this isn’t an issue as the script will be updated from the interface and you can copy and paste it. While you could copy and paste this token into a script, if (and when) the token expires or gets rolled, your script will break.
Instead of relying on the system provisioned token and copy/paste, we’ll create and store a token that will get passed to our containers and used to provision new instances. This has several key advantages:
- The lifecycle of the system provisioned data management token is not configurable.
- Using the Splunk UI or API to create your own lifecycle around the token ensures reliable and predictable instance provisioning.
- Using the token API allows for integration with existing CI/CD and credential management capabilities that are likely part of the autoscaling framework you’ll be using.
A dedicated, explicitly managed Splunk token should be used to provision instances in these autoscaling scenarios.
In both cases, the Splunk token authentication feature will be used. Knowledge of this feature and enabling it in your environment is a prerequisite for this workflow.
Recommended scenario: API token provisioning and managed credentials
Splunk provides a REST API for managing tokens. You can incorporate this API into whatever credential or secret management you intend to use with your autoscale and CI/CD frameworks. For a detailed description of tokens and token management, refer to the Splunk documentation.
Creating a token can be done in a single API call:
curl --location 'https://<control_plane_splunk_instance>:8089/services/authorization/tokens?output_mode=json' --header 'Content-Type: application/json' --header 'Authorization: Basic <my base auth value>' --data 'name=admin&audience=ep-instance&expires_on=%2B90d'
- The
audienceparameter can be any arbitrary value. - The
expires_onparameter should align with your credential rolling strategy.
The expected response is a JSON object that contains the token.
"content": {"eai:acl": null,"id": "90e66df3f4bff2969cc4855c927f919db78ae45ff294b336d836f34362dcaea4","token": "eyJraWQi...."}
This token should be captured and stored securely. It will be used in subsequent steps to provision Edge Processor instances.
These tokens must be created on the Splunk instance that is running the Edge Processor control plane. Do not create these on search heads, indexers, or other supporting Splunk infrastructure.
Basic scenario: Manual UI provisioning and management
Any valid token can be used to provision Edge Processor instances. You can find token management at https://$SPLUNK_HOME/en-US/manager/splunk_pipeline_builders/authorization/tokens
- Navigate to the token management screen and add a new token.
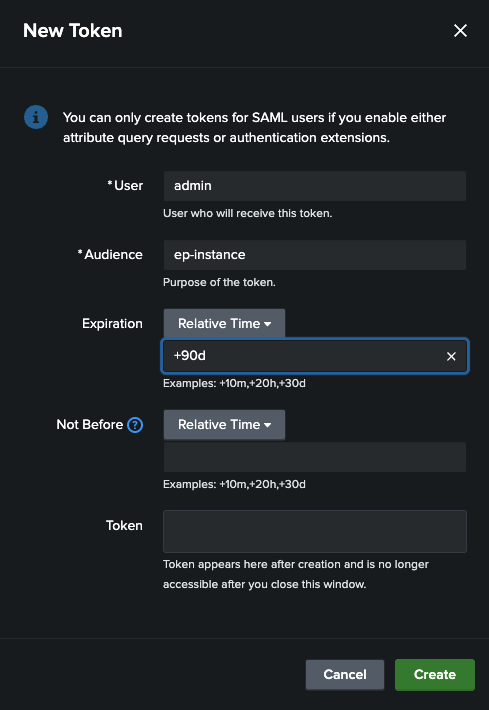
- The audience of ep-instance can be used for continuity of the system tokens or you can use your own. It does not matter for the purposes of provisioning Edge Processor instances. The expiration time fields will dictate when this token will no longer be able to provision instances. You should incorporate this into your security and container lifecycle policies.
- After you click Create, the token will be displayed once, and then never again.

Capture this token and store it securely for use in our containers in subsequent steps. If you do not capture the token, you will not be able to retrieve it later.
Next steps
Now that we understand how to get API tokens on demand, we can look at building out automation for scaling up Splunk Edge Processor nodes on-demand.