Reducing Smartstore cache churn with smart Workload Management rules
When using Smartstore in the Splunk platform, data indexed is stored in S3 storage, while the local hard drives (or SSD) on the indexers become Smartstore "cache" for the indexed buckets. This is demonstrated in the following architecture diagram:
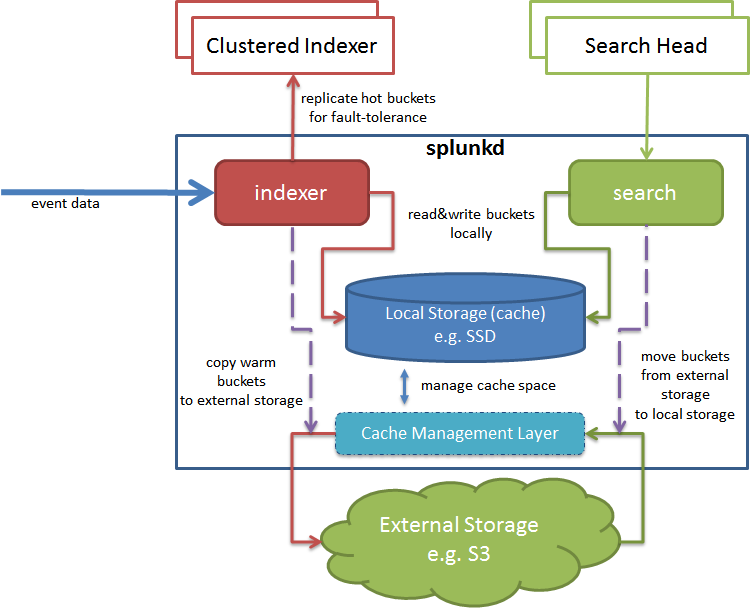
Efficient cache management is crucial when using Smartstore. The effectiveness of the cache manager is optimized when queries use recent data over a short time duration (for example, from 24 hours up to a few weeks, depending on the available cache) and have spatial and temporal locality.
However, users often run queries that deviate from these criteria. For instance, a user might search for the last 180 days of data on an index with high data ingestion. This can lead to a high cache miss rate, potentially causing the eviction of a large number of buckets from other indexes to make space for retrieving the requested data. This impacts not only the performance of that specific query but also any other queries, and even the performance of data ingestion.
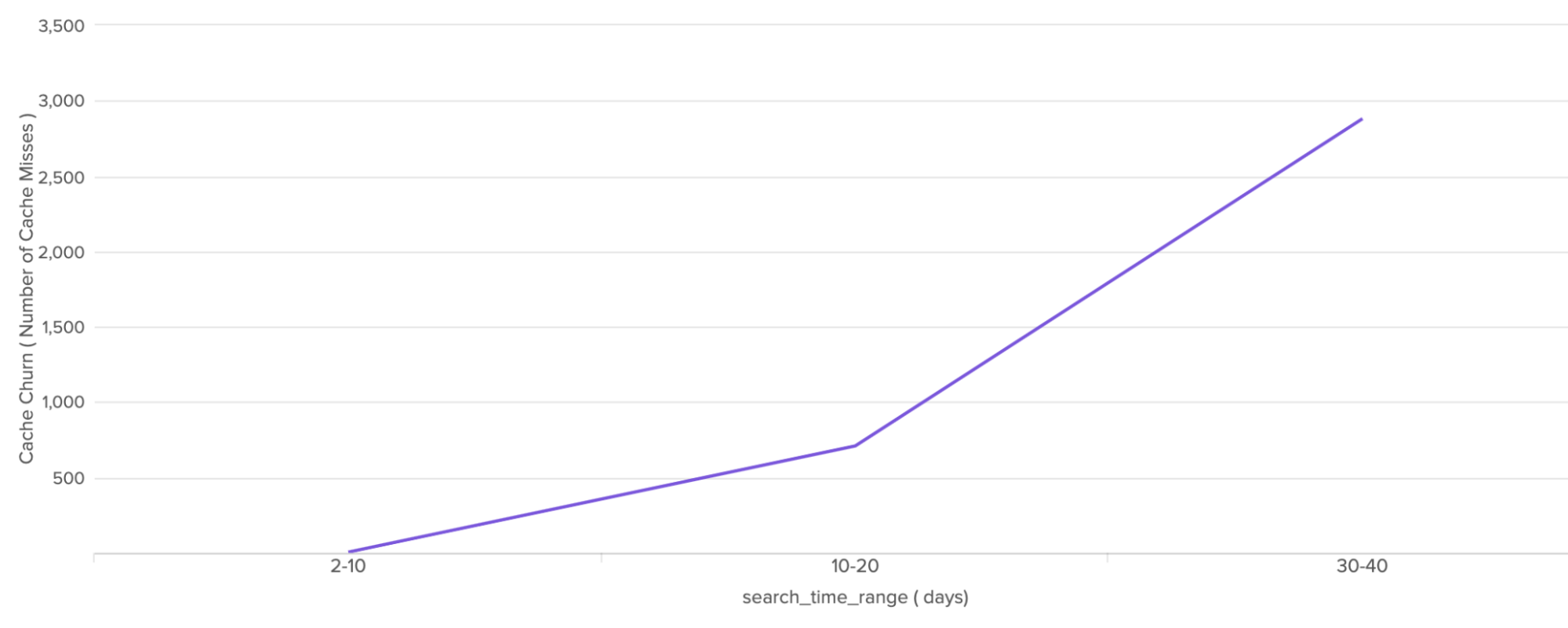
The following chart shows a comparison of cache churn versus search time range. The higher the search time range, the higher the number of cache misses.
How to use Splunk software for this use case
To address this challenge proactively, Splunk administrators can leverage a recently released feature in Workload Management (WLM). Starting with Splunk Cloud Platform 9.0.2305, administrators can define WLM rules under admission or workload rules using the search_time_duration predicate.
search_time_duration>24h AND role=novice_user → do not run the query
This rule filters queries written by users in the novice_user role that search for more than a 24-hour time window. It allows administrators to manage queries scanning large data sets across multiple buckets.
You can also tie this search to indexes to boost its effectiveness. Different indexes receive varying daily data volumes, so each one must scan different numbers of buckets over the same search time duration. For example, an index receiving firewall logs will have a significantly higher volume than an index with application build logs.
index=security_events AND search_time_duration>48h AND role!=security_user → do not run the query
In this example, the security_events index, a high-volume index, experiences significant cache churn when searching for more than 48 hours of data. The rule ensures that queries from non-security users searching beyond this duration are not executed.
If your system experiences cache churn issues, utilizing WLM rules tied to indexes provides a proactive approach to reduce risk and maintain a healthy Splunk instance.
Next steps
These resources might help you understand and implement this guidance:
- Splunk Help: Workload management examples