Organizing machine learning data flows
You can use the Splunk AI Toolkit (AITK) and the Splunk App for Data Science and Deep Learning (DSDL) to address security, operations, DevOps or business use cases. However, when setting these apps up, it might not always be clear how best to organize the data flow in Splunk Enterprise or Splunk Cloud Platform.
You can use basic, intermediate or advanced patterns, depending on the complexity of your use case, which will help you improve your existing or future machine learning workflows with AITK or DSDL.
Basic pattern: Directly fit and apply
The AITK relies mostly on the classical machine learning paradigm of “fit and apply”, where usually there are two main moving parts.
- You can train a model with the
| fit … into modelstatement:- Either in an ad-hoc search, for example, for scoring your model
- Or in a scheduled search, for example, for retraining your model in a continuous way.
- Then you can use another search that uses
| apply modelto run it:- Either ad-hoc on new data
- Or in a scheduled search that generates a report or an alert based on your model results.
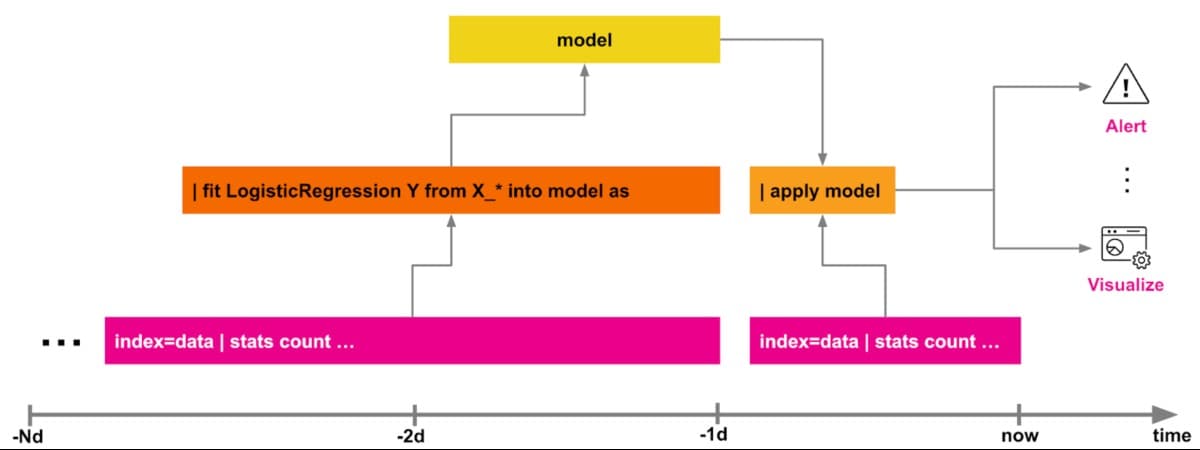
This basic pattern works fine for many simple use cases and you can create productive machine learning pipelines with AITK. While this pattern is great for quick and ad-hoc tasks, you will probably need to move on to another stage when your data flows get more complicated.
Intermediate pattern: Summary indexing
This pattern could be a good option for you when your model depends on multiple data sources and involves heavier SPL lifting. You might find you need a pattern like this when you need more preprocessing steps like data transformations for cleaning, merging, munging, or feature engineering in general.
Using summary indexing (in Enterprise or Cloud Platform) you can write search results as key=value pairs into an arbitrarily defined event index, or into a metrics index for purely numerical time series data. For more information see workload management documentation for Enterprise or Cloud Platform.
This helps offload ongoing calculations of features and statistics into a separate index. A separate index is often much faster to query instead of searches which run repeated heavy computations on large sets of historical data. Data models (in Enterprise or Cloud Platform) can also be used to accelerate the process.
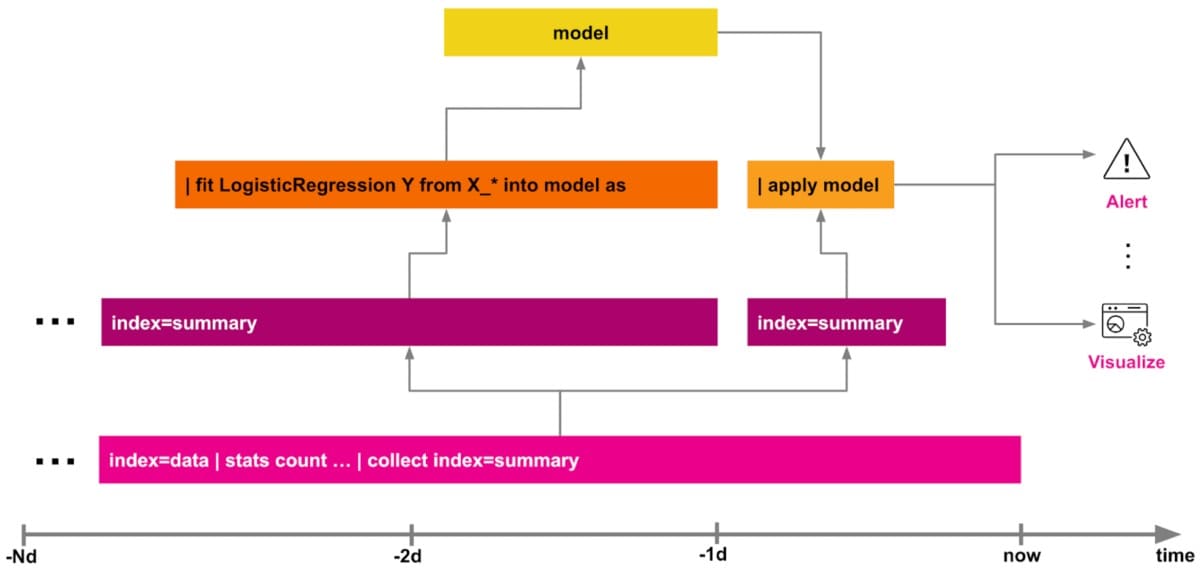
For AITK, you will need to run your | fit on a summary index or a data model instead of the raw data. This can significantly speed up overall processing time, especially when there is more more heavy lifting required on the SPL side.
As the | apply is often computationally not as demanding as the | fit, you can either apply all transformations on the new raw indexed data then or - with a certain time lag - on the summary indexed data.
Advanced pattern: Enrichment with feedback
This pattern uses the human-in-the-loop type of machine learning systems that allow users to add further data into the training pipeline. This data could either be additional features in terms of synthetically generated data points, or changing parameters - for example, to adjust the sensitivity of an anomaly detection model.

As long as the feedback can change over time but is related to some unique identifier, then the Splunk KVStore (in Enterprise or Cloud Platform) is a good fit for that requirement and allows for further enrichment of the training data, for example by incorporating user generated labels for a classifier model. The DGA App for Splunk shows an example for that pattern that could help you get started quickly.
You could also combine the KVStore with summary indexing to keep track of all changes over time. This method can be useful for auditing purposes, as well as to create another data layer which can be utilized for further supervised learning tasks, as it contains labels generated for the given cases.
Next steps
The content in this guide comes from a previously published blog, one of the thousands of Splunk resources available to help users succeed. In addition, these Splunk resources might help you understand and implement this use case: